{"title":"Semantic similarity loss for neural source code summarization","authors":"Chia-Yi Su, Collin McMillan","doi":"10.1002/smr.2706","DOIUrl":null,"url":null,"abstract":"<p>This paper presents a procedure for and evaluation of using a semantic similarity metric as a loss function for neural source code summarization. Code summarization is the task of writing natural language descriptions of source code. Neural code summarization refers to automated techniques for generating these descriptions using neural networks. Almost all current approaches involve neural networks as either standalone models or as part of a pretrained large language models, for example, GPT, Codex, and LLaMA. Yet almost all also use a categorical cross-entropy (CCE) loss function for network optimization. Two problems with CCE are that (1) it computes loss over each word prediction one-at-a-time, rather than evaluating a whole sentence, and (2) it requires a perfect prediction, leaving no room for partial credit for synonyms. In this paper, we extend our previous work on semantic similarity metrics to show a procedure for using semantic similarity as a loss function to alleviate this problem, and we evaluate this procedure in several settings in both metrics-driven and human studies. In essence, we propose to use a semantic similarity metric to calculate loss over the whole output sentence prediction per training batch, rather than just loss for each word. We also propose to combine our loss with CCE for each word, which streamlines the training process compared to baselines. We evaluate our approach over several baselines and report improvement in the vast majority of conditions.</p>","PeriodicalId":48898,"journal":{"name":"Journal of Software-Evolution and Process","volume":"36 11","pages":""},"PeriodicalIF":1.7000,"publicationDate":"2024-07-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Software-Evolution and Process","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/smr.2706","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
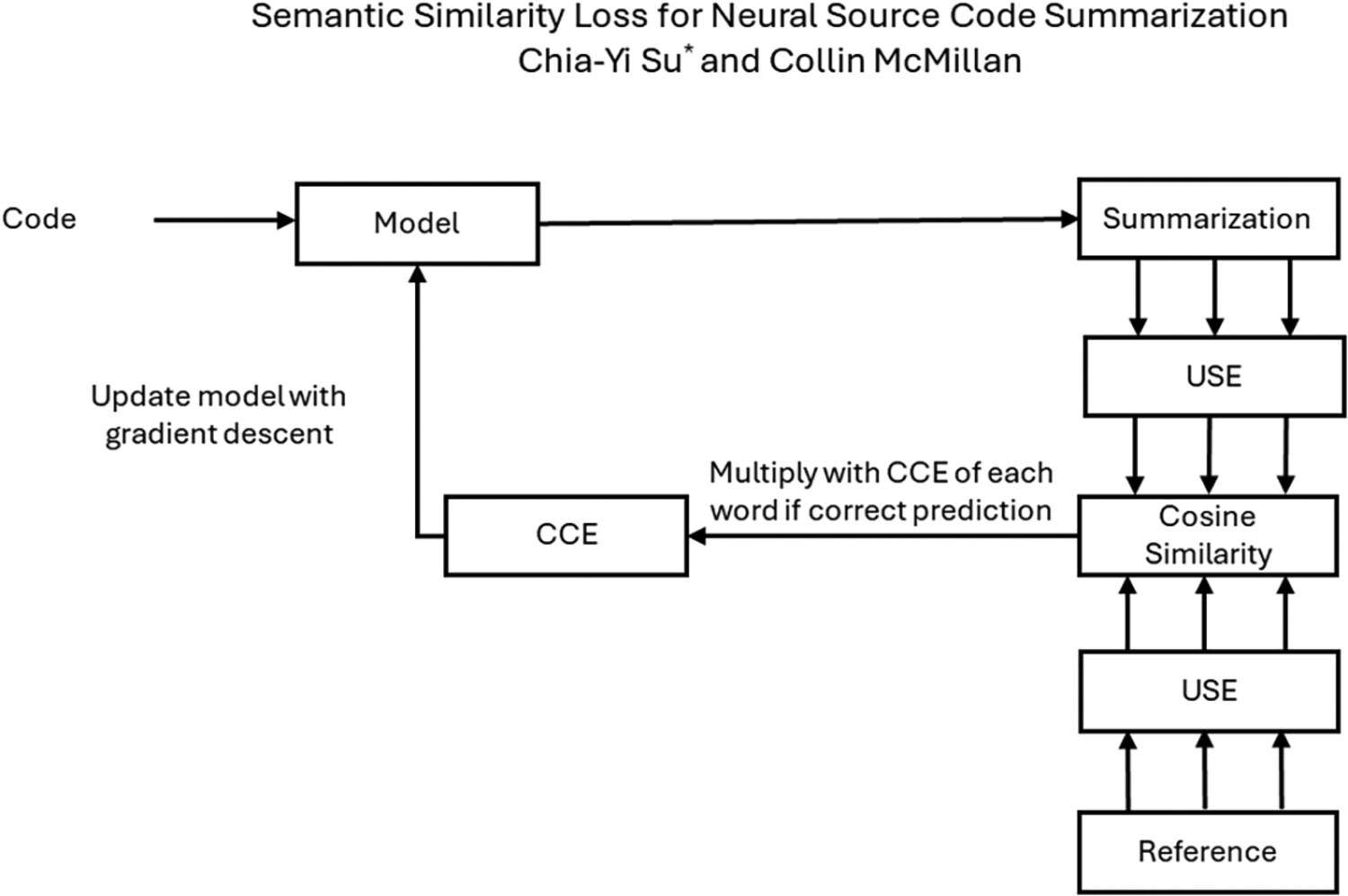
This paper presents a procedure for and evaluation of using a semantic similarity metric as a loss function for neural source code summarization. Code summarization is the task of writing natural language descriptions of source code. Neural code summarization refers to automated techniques for generating these descriptions using neural networks. Almost all current approaches involve neural networks as either standalone models or as part of a pretrained large language models, for example, GPT, Codex, and LLaMA. Yet almost all also use a categorical cross-entropy (CCE) loss function for network optimization. Two problems with CCE are that (1) it computes loss over each word prediction one-at-a-time, rather than evaluating a whole sentence, and (2) it requires a perfect prediction, leaving no room for partial credit for synonyms. In this paper, we extend our previous work on semantic similarity metrics to show a procedure for using semantic similarity as a loss function to alleviate this problem, and we evaluate this procedure in several settings in both metrics-driven and human studies. In essence, we propose to use a semantic similarity metric to calculate loss over the whole output sentence prediction per training batch, rather than just loss for each word. We also propose to combine our loss with CCE for each word, which streamlines the training process compared to baselines. We evaluate our approach over several baselines and report improvement in the vast majority of conditions.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


