{"title":"FEF-Net: feature enhanced fusion network with crossmodal attention for multimodal humor prediction","authors":"Peng Gao, Chuanqi Tao, Donghai Guan","doi":"10.1007/s00530-024-01402-z","DOIUrl":null,"url":null,"abstract":"<p>Humor segment prediction in video involves the comprehension and analysis of humor. Traditional humor prediction has been text-based; however, with the evolution of multimedia, the focus has shifted to multimodal approaches in humor prediction, marking a current trend in research. In recent years, determining whether a video is humorous has remained a challenge within the domain of sentiment analysis. Researchers have proposed multiple data fusion methods to address humor prediction and sentiment analysis. Within the realm of studying humor and emotions, text modality assumes a leading role, while audio and video modalities serve as supplementary data sources for multimodal humor prediction. However, these auxiliary modalities contain significant irrelevant information unrelated to the prediction task, resulting in redundancy. Current multimodal fusion models primarily emphasize fusion methods but overlook the issue of high redundancy in auxiliary modalities. The lack of research on reducing redundancy in auxiliary modalities introduces noise, thereby increasing the overall training complexity of models and diminishing predictive accuracy. Hence, developing a humor prediction method that effectively reduces redundancy in auxiliary modalities is pivotal for advancing multimodal research. In this paper, we propose the Feature Enhanced Fusion Network (FEF-Net), leveraging cross-modal attention to augment features from auxiliary modalities using knowledge from textual data. This mechanism generates weights to emphasize the redundancy of each corresponding time slice in the auxiliary modality. Further, employing Transformer encoders extracts high-level features for each modality, thereby enhancing the performance of humor prediction models. Experimental comparisons were conducted using the UR-FUNNY and MUStARD multimodal humor prediction models, revealing a 3.2% improvement in ‘Acc-2’ compared to the optimal model.</p>","PeriodicalId":3,"journal":{"name":"ACS Applied Electronic Materials","volume":null,"pages":null},"PeriodicalIF":4.3000,"publicationDate":"2024-07-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"ACS Applied Electronic Materials","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00530-024-01402-z","RegionNum":3,"RegionCategory":"材料科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"ENGINEERING, ELECTRICAL & ELECTRONIC","Score":null,"Total":0}
引用次数: 0
Abstract
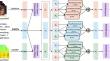
Humor segment prediction in video involves the comprehension and analysis of humor. Traditional humor prediction has been text-based; however, with the evolution of multimedia, the focus has shifted to multimodal approaches in humor prediction, marking a current trend in research. In recent years, determining whether a video is humorous has remained a challenge within the domain of sentiment analysis. Researchers have proposed multiple data fusion methods to address humor prediction and sentiment analysis. Within the realm of studying humor and emotions, text modality assumes a leading role, while audio and video modalities serve as supplementary data sources for multimodal humor prediction. However, these auxiliary modalities contain significant irrelevant information unrelated to the prediction task, resulting in redundancy. Current multimodal fusion models primarily emphasize fusion methods but overlook the issue of high redundancy in auxiliary modalities. The lack of research on reducing redundancy in auxiliary modalities introduces noise, thereby increasing the overall training complexity of models and diminishing predictive accuracy. Hence, developing a humor prediction method that effectively reduces redundancy in auxiliary modalities is pivotal for advancing multimodal research. In this paper, we propose the Feature Enhanced Fusion Network (FEF-Net), leveraging cross-modal attention to augment features from auxiliary modalities using knowledge from textual data. This mechanism generates weights to emphasize the redundancy of each corresponding time slice in the auxiliary modality. Further, employing Transformer encoders extracts high-level features for each modality, thereby enhancing the performance of humor prediction models. Experimental comparisons were conducted using the UR-FUNNY and MUStARD multimodal humor prediction models, revealing a 3.2% improvement in ‘Acc-2’ compared to the optimal model.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


