Andrea Santangeli, Stefano Mammola, Veronica Nanni, Sergio A. Lambertucci
{"title":"Large language models debunk fake and sensational wildlife news\n 通过大型语言模型揭露虚假和耸人听闻的野生动物新闻","authors":"Andrea Santangeli, Stefano Mammola, Veronica Nanni, Sergio A. Lambertucci","doi":"10.1002/inc3.55","DOIUrl":null,"url":null,"abstract":"<p>In the current era of rapid online information growth, distinguishing facts from sensationalized or fake content is a major challenge. Here, we explore the potential of large language models as a tool to fact-check fake news and sensationalized content about animals. We queried the most popular large language models (ChatGPT 3.5 and 4, and Microsoft Bing), asking them to quantify the likelihood of 14 wildlife groups, often portrayed as dangerous or sensationalized, killing humans or livestock. We then compared these scores with the “real” risk obtained from relevant literature and/or expert opinion. We found a positive relationship between the likelihood risk score obtained from large language models and the “real” risk. This indicates the promising potential of large language models in fact-checking information about commonly misrepresented and widely feared animals, including jellyfish, wasps, spiders, vultures, and various large carnivores. Our analysis underscores the crucial role of large language models in dispelling wildlife myths, helping to mitigate human–wildlife conflicts, shaping a more just and harmonious coexistence, and ultimately aiding biological conservation.</p>","PeriodicalId":100680,"journal":{"name":"Integrative Conservation","volume":"3 2","pages":"127-133"},"PeriodicalIF":0.0000,"publicationDate":"2024-06-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/inc3.55","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Integrative Conservation","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/inc3.55","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
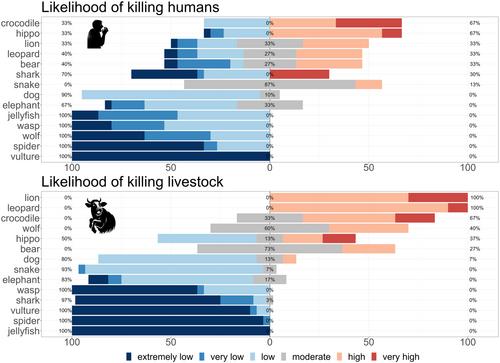
In the current era of rapid online information growth, distinguishing facts from sensationalized or fake content is a major challenge. Here, we explore the potential of large language models as a tool to fact-check fake news and sensationalized content about animals. We queried the most popular large language models (ChatGPT 3.5 and 4, and Microsoft Bing), asking them to quantify the likelihood of 14 wildlife groups, often portrayed as dangerous or sensationalized, killing humans or livestock. We then compared these scores with the “real” risk obtained from relevant literature and/or expert opinion. We found a positive relationship between the likelihood risk score obtained from large language models and the “real” risk. This indicates the promising potential of large language models in fact-checking information about commonly misrepresented and widely feared animals, including jellyfish, wasps, spiders, vultures, and various large carnivores. Our analysis underscores the crucial role of large language models in dispelling wildlife myths, helping to mitigate human–wildlife conflicts, shaping a more just and harmonious coexistence, and ultimately aiding biological conservation.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


