Scanorama: integrating large and diverse single-cell transcriptomic datasets
IF 13.1
1区 生物学
Q1 BIOCHEMICAL RESEARCH METHODS
引用次数: 0
Abstract
Merging diverse single-cell RNA sequencing (scRNA-seq) data from numerous experiments, laboratories and technologies can uncover important biological insights. Nonetheless, integrating scRNA-seq data encounters special challenges when the datasets are composed of diverse cell type compositions. Scanorama offers a robust solution for improving the quality and interpretation of heterogeneous scRNA-seq data by effectively merging information from diverse sources. Scanorama is designed to address the technical variation introduced by differences in sample preparation, sequencing depth and experimental batches that can confound the analysis of multiple scRNA-seq datasets. Here we provide a detailed protocol for using Scanorama within a Scanpy-based single-cell analysis workflow coupled with Google Colaboratory, a cloud-based free Jupyter notebook environment service. The protocol involves Scanorama integration, a process that typically spans 0.5–3 h. Scanorama integration requires a basic understanding of cellular biology, transcriptomic technologies and bioinformatics. Our protocol and new Scanorama–Colaboratory resource should make scRNA-seq integration more widely accessible to researchers. Scanorama is an effective tool for combining multiple single-cell RNA sequencing datasets, addressing technical variation introduced by differences in sample preparation, sequencing depth and experimental batches that can confound the analysis of diverse datasets.
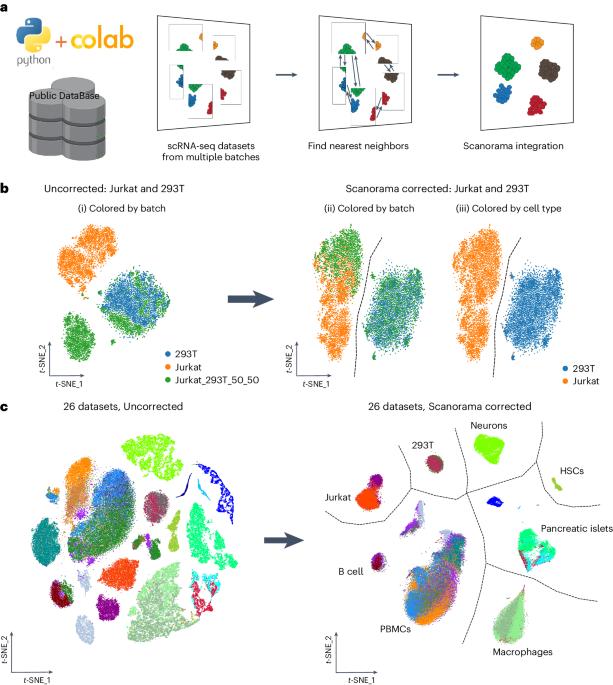
Scanorama:整合大型多样的单细胞转录组数据集。
合并来自众多实验、实验室和技术的不同单细胞 RNA 测序(scRNA-seq)数据,可以发现重要的生物学见解。然而,当数据集由不同的细胞类型组成时,整合 scRNA-seq 数据就会遇到特殊的挑战。Scanorama 通过有效合并不同来源的信息,为提高异构 scRNA-seq 数据的质量和解释提供了强大的解决方案。Scanorama 旨在解决样本制备、测序深度和实验批次的不同所带来的技术差异,这些差异可能会干扰多个 scRNA-seq 数据集的分析。在这里,我们提供了在基于 Scanpy 的单细胞分析工作流中使用 Scanorama 的详细方案,该工作流与基于云的免费 Jupyter 笔记本环境服务 Google Colaboratory 相结合。Scanorama 整合需要对细胞生物学、转录组技术和生物信息学有基本的了解。我们的方案和新的 Scanorama-Colaboratory 资源应能让研究人员更广泛地使用 scRNA-seq 整合。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊
Nature Protocols
生物-生化研究方法
CiteScore
29.10
自引率
0.70%
发文量
128
审稿时长
4 months
期刊介绍:
Nature Protocols focuses on publishing protocols used to address significant biological and biomedical science research questions, including methods grounded in physics and chemistry with practical applications to biological problems. The journal caters to a primary audience of research scientists and, as such, exclusively publishes protocols with research applications. Protocols primarily aimed at influencing patient management and treatment decisions are not featured.
The specific techniques covered encompass a wide range, including but not limited to: Biochemistry, Cell biology, Cell culture, Chemical modification, Computational biology, Developmental biology, Epigenomics, Genetic analysis, Genetic modification, Genomics, Imaging, Immunology, Isolation, purification, and separation, Lipidomics, Metabolomics, Microbiology, Model organisms, Nanotechnology, Neuroscience, Nucleic-acid-based molecular biology, Pharmacology, Plant biology, Protein analysis, Proteomics, Spectroscopy, Structural biology, Synthetic chemistry, Tissue culture, Toxicology, and Virology.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


