Intelligent Decision-Making System of Air Defense Resource Allocation via Hierarchical Reinforcement Learning
Abstract
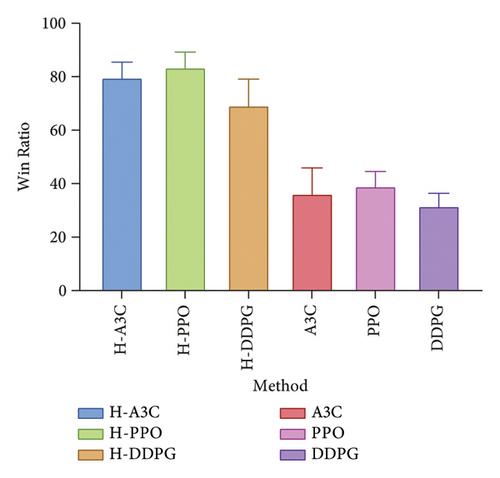
Intelligent decision-making in air defense operations has attracted wide attention from researchers. Facing complex battlefield environments, existing decision-making algorithms fail to make targeted decisions according to the hierarchical decision-making characteristics of air defense operational command and control. What’s worse, in the process of problem-solving, these algorithms are beset by defects such as dimensional disaster and poor real-time performance. To address these problems, a new hierarchical reinforcement learning algorithm named Hierarchy Asynchronous Advantage Actor-Critic (H-A3C) is developed. This algorithm is designed to have a hierarchical decision-making framework considering the characteristics of air defense operations and employs the hierarchical reinforcement learning method for problem-solving. With a hierarchical decision-making capability similar to that of human commanders in decision-making, the developed algorithm produces many new policies during the learning process. The features of air situation information are extracted using the bidirectional-gated recurrent unit (Bi-GRU) network, and then the agent is trained using the H-A3C algorithm. In the training process, the multihead attention mechanism and the event-based reward mechanism are introduced to facilitate the training. In the end, the proposed H-A3C algorithm is verified in a digital battlefield environment, and the results prove its advantages over existing algorithms.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


