Zuqin Chen, Yujie Zheng, Jike Ge, Wencheng Yu, Zining Wang
{"title":"A Parallel Model for Jointly Extracting Entities and Relations","authors":"Zuqin Chen, Yujie Zheng, Jike Ge, Wencheng Yu, Zining Wang","doi":"10.1007/s11063-024-11616-x","DOIUrl":null,"url":null,"abstract":"<p>Extracting relational triples from a piece of text is an essential task in knowledge graph construction. However, most existing methods either identify entities before predicting their relations, or detect relations before recognizing associated entities. This order may lead to error accumulation because once there is an error in the initial step, it will accumulate to subsequent steps. To solve this problem, we propose a parallel model for jointly extracting entities and relations, called PRE-Span, which consists of two mutually independent submodules. Specifically, candidate entities and relations are first generated by enumerating token sequences in sentences. Then, two independent submodules (Entity Extraction Module and Relation Detection Module) are designed to predict entities and relations. Finally, the predicted results of the two submodules are analyzed to select entities and relations, which are jointly decoded to obtain relational triples. The advantage of this method is that all triples can be extracted in just one step. Extensive experiments on the WebNLG*, NYT*, NYT and WebNLG datasets show that our model outperforms other baselines at 94.4%, 88.3%, 86.5% and 83.0%, respectively.</p>","PeriodicalId":51144,"journal":{"name":"Neural Processing Letters","volume":"17 1","pages":""},"PeriodicalIF":2.8000,"publicationDate":"2024-05-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Neural Processing Letters","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11063-024-11616-x","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
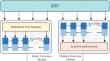
Extracting relational triples from a piece of text is an essential task in knowledge graph construction. However, most existing methods either identify entities before predicting their relations, or detect relations before recognizing associated entities. This order may lead to error accumulation because once there is an error in the initial step, it will accumulate to subsequent steps. To solve this problem, we propose a parallel model for jointly extracting entities and relations, called PRE-Span, which consists of two mutually independent submodules. Specifically, candidate entities and relations are first generated by enumerating token sequences in sentences. Then, two independent submodules (Entity Extraction Module and Relation Detection Module) are designed to predict entities and relations. Finally, the predicted results of the two submodules are analyzed to select entities and relations, which are jointly decoded to obtain relational triples. The advantage of this method is that all triples can be extracted in just one step. Extensive experiments on the WebNLG*, NYT*, NYT and WebNLG datasets show that our model outperforms other baselines at 94.4%, 88.3%, 86.5% and 83.0%, respectively.
期刊介绍:
Neural Processing Letters is an international journal publishing research results and innovative ideas on all aspects of artificial neural networks. Coverage includes theoretical developments, biological models, new formal modes, learning, applications, software and hardware developments, and prospective researches.
The journal promotes fast exchange of information in the community of neural network researchers and users. The resurgence of interest in the field of artificial neural networks since the beginning of the 1980s is coupled to tremendous research activity in specialized or multidisciplinary groups. Research, however, is not possible without good communication between people and the exchange of information, especially in a field covering such different areas; fast communication is also a key aspect, and this is the reason for Neural Processing Letters

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


