Muharrem Baturu, Mehmet Solakhan, Tanyeli Guneyligil Kazaz, Omer Bayrak
{"title":"Frequently asked questions on erectile dysfunction: evaluating artificial intelligence answers with expert mentorship.","authors":"Muharrem Baturu, Mehmet Solakhan, Tanyeli Guneyligil Kazaz, Omer Bayrak","doi":"10.1038/s41443-024-00898-3","DOIUrl":null,"url":null,"abstract":"<p><p>The present study assessed the accuracy of artificiaI intelligence-generated responses to frequently asked questions on erectile dysfunction. A cross-sectional analysis involved 56 erectile dysfunction-related questions searched on Google, categorized into nine sections: causes, diagnosis, treatment options, treatment complications, protective measures, relationship with other illnesses, treatment costs, treatment with herbal agents, and appointments. Responses from ChatGPT 3.5, ChatGPT 4, and BARD were evaluated by two experienced urology experts using the F1 and global quality scores (GQS) for accuracy, relevance, and comprehensibility. ChatGPT 3.5 and ChatGPT 4 achieved higher GQS than BARD in categories such as causes (4.5 ± 0.54, 4.5 ± 0.51, 3.15 ± 1.01, respectively, p < 0.001), treatment options (4.35 ± 0.6, 4.5 ± 0.43, 2.71 ± 1.38, respectively, p < 0.001), protective measures (5.0 ± 0, 5.0 ± 0, 4 ± 0.5, respectively, p = 0.013), relationships with other illnesses (4.58 ± 0.58, 4.83 ± 0.25, 3.58 ± 0.8, respectively, p = 0.006), and treatment with herbal agents (3 ± 0.61, 3.33 ± 0.83, 1.8 ± 1.09, respectively, p = 0.043). F1 scores in categories: causes (1), diagnosis (0.857), treatment options (0.726), and protective measures (1), indicated their alignment with the guidelines. There was no significant difference between ChatGPT 3.5 and ChatGPT 4 regarding answer quality, but both outperformed BARD in the GQS. These results emphasize the need to continually enhance and validate AI-generated medical information, underscoring the importance of artificiaI intelligence systems in delivering reliable information on erectile dysfunction.</p>","PeriodicalId":14068,"journal":{"name":"International Journal of Impotence Research","volume":" ","pages":"310-314"},"PeriodicalIF":2.5000,"publicationDate":"2025-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Impotence Research","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1038/s41443-024-00898-3","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/5/7 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"UROLOGY & NEPHROLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
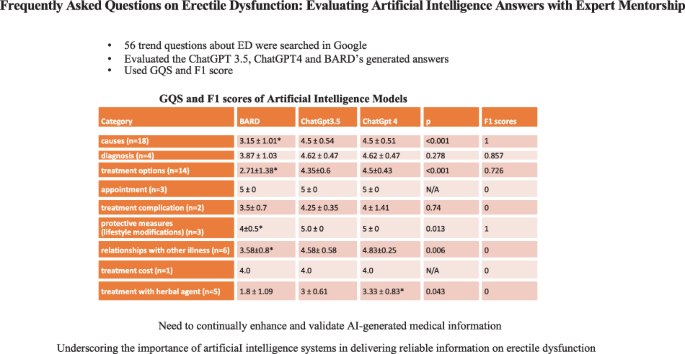
The present study assessed the accuracy of artificiaI intelligence-generated responses to frequently asked questions on erectile dysfunction. A cross-sectional analysis involved 56 erectile dysfunction-related questions searched on Google, categorized into nine sections: causes, diagnosis, treatment options, treatment complications, protective measures, relationship with other illnesses, treatment costs, treatment with herbal agents, and appointments. Responses from ChatGPT 3.5, ChatGPT 4, and BARD were evaluated by two experienced urology experts using the F1 and global quality scores (GQS) for accuracy, relevance, and comprehensibility. ChatGPT 3.5 and ChatGPT 4 achieved higher GQS than BARD in categories such as causes (4.5 ± 0.54, 4.5 ± 0.51, 3.15 ± 1.01, respectively, p < 0.001), treatment options (4.35 ± 0.6, 4.5 ± 0.43, 2.71 ± 1.38, respectively, p < 0.001), protective measures (5.0 ± 0, 5.0 ± 0, 4 ± 0.5, respectively, p = 0.013), relationships with other illnesses (4.58 ± 0.58, 4.83 ± 0.25, 3.58 ± 0.8, respectively, p = 0.006), and treatment with herbal agents (3 ± 0.61, 3.33 ± 0.83, 1.8 ± 1.09, respectively, p = 0.043). F1 scores in categories: causes (1), diagnosis (0.857), treatment options (0.726), and protective measures (1), indicated their alignment with the guidelines. There was no significant difference between ChatGPT 3.5 and ChatGPT 4 regarding answer quality, but both outperformed BARD in the GQS. These results emphasize the need to continually enhance and validate AI-generated medical information, underscoring the importance of artificiaI intelligence systems in delivering reliable information on erectile dysfunction.
期刊介绍:
International Journal of Impotence Research: The Journal of Sexual Medicine addresses sexual medicine for both genders as an interdisciplinary field. This includes basic science researchers, urologists, endocrinologists, cardiologists, family practitioners, gynecologists, internists, neurologists, psychiatrists, psychologists, radiologists and other health care clinicians.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


