{"title":"DepthGAN: GAN-based depth generation from semantic layouts","authors":"Yidi Li, Jun Xiao, Yiqun Wang, Zhengda Lu","doi":"10.1007/s41095-023-0350-8","DOIUrl":null,"url":null,"abstract":"<p>Existing GAN-based generative methods are typically used for semantic image synthesis. We pose the question of whether GAN-based architectures can generate plausible depth maps and find that existing methods have difficulty in generating depth maps which reasonably represent 3D scene structure due to the lack of global geometric correlations. Thus, we propose DepthGAN, a novel method of generating a depth map using a semantic layout as input to aid construction, and manipulation of well-structured 3D scene point clouds. Specifically, we first build a feature generation model with a cascade of semantically-aware transformer blocks to obtain depth features with global structural information. For our semantically aware transformer block, we propose a mixed attention module and a semantically aware layer normalization module to better exploit semantic consistency for depth features generation. Moreover, we present a novel semantically weighted depth synthesis module, which generates adaptive depth intervals for the current scene. We generate the final depth map by using a weighted combination of semantically aware depth weights for different depth ranges. In this manner, we obtain a more accurate depth map. Extensive experiments on indoor and outdoor datasets demonstrate that DepthGAN achieves superior results both quantitatively and visually for the depth generation task.\n</p>","PeriodicalId":37301,"journal":{"name":"Computational Visual Media","volume":"72 1","pages":""},"PeriodicalIF":18.3000,"publicationDate":"2024-04-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Visual Media","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s41095-023-0350-8","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
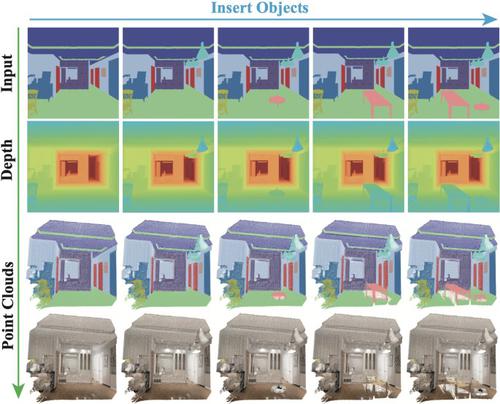
Existing GAN-based generative methods are typically used for semantic image synthesis. We pose the question of whether GAN-based architectures can generate plausible depth maps and find that existing methods have difficulty in generating depth maps which reasonably represent 3D scene structure due to the lack of global geometric correlations. Thus, we propose DepthGAN, a novel method of generating a depth map using a semantic layout as input to aid construction, and manipulation of well-structured 3D scene point clouds. Specifically, we first build a feature generation model with a cascade of semantically-aware transformer blocks to obtain depth features with global structural information. For our semantically aware transformer block, we propose a mixed attention module and a semantically aware layer normalization module to better exploit semantic consistency for depth features generation. Moreover, we present a novel semantically weighted depth synthesis module, which generates adaptive depth intervals for the current scene. We generate the final depth map by using a weighted combination of semantically aware depth weights for different depth ranges. In this manner, we obtain a more accurate depth map. Extensive experiments on indoor and outdoor datasets demonstrate that DepthGAN achieves superior results both quantitatively and visually for the depth generation task.
现有的基于 GAN 的生成方法通常用于语义图像合成。我们提出了基于 GAN 的架构能否生成可信深度图的问题,并发现由于缺乏全局几何相关性,现有方法难以生成合理表现三维场景结构的深度图。因此,我们提出了 DepthGAN,一种使用语义布局作为输入来生成深度图的新方法,以帮助构建和操作结构良好的三维场景点云。具体来说,我们首先利用语义感知转换块级联建立一个特征生成模型,以获取具有全局结构信息的深度特征。对于语义感知转换模块,我们提出了混合注意力模块和语义感知层归一化模块,以更好地利用语义一致性生成深度特征。此外,我们还提出了一个新颖的语义加权深度合成模块,它能为当前场景生成自适应深度区间。我们通过对不同深度范围的语义深度权重进行加权组合,生成最终的深度图。通过这种方式,我们获得了更精确的深度图。在室内和室外数据集上进行的大量实验表明,DepthGAN 在深度生成任务的定量和视觉效果上都取得了卓越的成果。
期刊介绍:
Computational Visual Media is a peer-reviewed open access journal. It publishes original high-quality research papers and significant review articles on novel ideas, methods, and systems relevant to visual media.
Computational Visual Media publishes articles that focus on, but are not limited to, the following areas:
• Editing and composition of visual media
• Geometric computing for images and video
• Geometry modeling and processing
• Machine learning for visual media
• Physically based animation
• Realistic rendering
• Recognition and understanding of visual media
• Visual computing for robotics
• Visualization and visual analytics
Other interdisciplinary research into visual media that combines aspects of computer graphics, computer vision, image and video processing, geometric computing, and machine learning is also within the journal''s scope.
This is an open access journal, published quarterly by Tsinghua University Press and Springer. The open access fees (article-processing charges) are fully sponsored by Tsinghua University, China. Authors can publish in the journal without any additional charges.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


