Yudi Li, Min Tang, Yun Yang, Ruofeng Tong, Shuangcai Yang, Yao Li, Bailin An, Qilong Kou
{"title":"CTSN: Predicting cloth deformation for skeleton-based characters with a two-stream skinning network","authors":"Yudi Li, Min Tang, Yun Yang, Ruofeng Tong, Shuangcai Yang, Yao Li, Bailin An, Qilong Kou","doi":"10.1007/s41095-023-0344-6","DOIUrl":null,"url":null,"abstract":"<p>We present a novel learning method using a two-stream network to predict cloth deformation for skeleton-based characters. The characters processed in our approach are not limited to humans, and can be other targets with skeleton-based representations such as fish or pets. We use a novel network architecture which consists of skeleton-based and mesh-based residual networks to learn the coarse features and wrinkle features forming the overall residual from the template cloth mesh. Our network may be used to predict the deformation for loose or tight-fitting clothing. The memory footprint of our network is low, thereby resulting in reduced computational requirements. In practice, a prediction for a single cloth mesh for a skeleton-based character takes about 7 ms on an nVidia GeForce RTX 3090 GPU. Compared to prior methods, our network can generate finer deformation results with details and wrinkles.\n</p>","PeriodicalId":37301,"journal":{"name":"Computational Visual Media","volume":"241 1","pages":""},"PeriodicalIF":18.3000,"publicationDate":"2024-04-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Visual Media","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s41095-023-0344-6","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
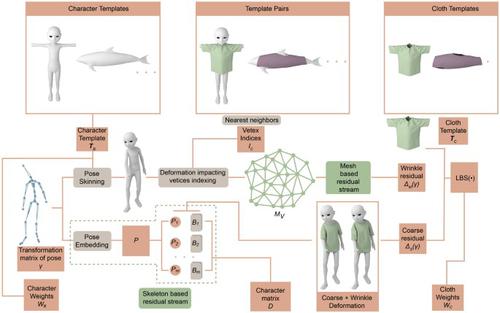
We present a novel learning method using a two-stream network to predict cloth deformation for skeleton-based characters. The characters processed in our approach are not limited to humans, and can be other targets with skeleton-based representations such as fish or pets. We use a novel network architecture which consists of skeleton-based and mesh-based residual networks to learn the coarse features and wrinkle features forming the overall residual from the template cloth mesh. Our network may be used to predict the deformation for loose or tight-fitting clothing. The memory footprint of our network is low, thereby resulting in reduced computational requirements. In practice, a prediction for a single cloth mesh for a skeleton-based character takes about 7 ms on an nVidia GeForce RTX 3090 GPU. Compared to prior methods, our network can generate finer deformation results with details and wrinkles.
期刊介绍:
Computational Visual Media is a peer-reviewed open access journal. It publishes original high-quality research papers and significant review articles on novel ideas, methods, and systems relevant to visual media.
Computational Visual Media publishes articles that focus on, but are not limited to, the following areas:
• Editing and composition of visual media
• Geometric computing for images and video
• Geometry modeling and processing
• Machine learning for visual media
• Physically based animation
• Realistic rendering
• Recognition and understanding of visual media
• Visual computing for robotics
• Visualization and visual analytics
Other interdisciplinary research into visual media that combines aspects of computer graphics, computer vision, image and video processing, geometric computing, and machine learning is also within the journal''s scope.
This is an open access journal, published quarterly by Tsinghua University Press and Springer. The open access fees (article-processing charges) are fully sponsored by Tsinghua University, China. Authors can publish in the journal without any additional charges.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


