{"title":"Developing a hierarchical model for unraveling conspiracy theories","authors":"Mohsen Ghasemizade, Jeremiah Onaolapo","doi":"10.1140/epjds/s13688-024-00470-5","DOIUrl":null,"url":null,"abstract":"<p>A conspiracy theory (CT) suggests covert groups or powerful individuals secretly manipulate events. Not knowing about existing conspiracy theories could make one more likely to believe them, so this work aims to compile a list of CTs shaped as a tree that is as comprehensive as possible. We began with a manually curated ‘tree’ of CTs from academic papers and Wikipedia. Next, we examined 1769 CT-related articles from four fact-checking websites, focusing on their core content, and used a technique called Keyphrase Extraction to label the documents. This process yielded 769 identified conspiracies, each assigned a label and a family name. The second goal of this project was to detect whether an article is a conspiracy theory, so we built a binary classifier with our labeled dataset. This model uses a transformer-based machine learning technique and is pre-trained on a large corpus called RoBERTa, resulting in an F1 score of 87%. This model helps to identify potential conspiracy theories in new articles. We used a combination of clustering (HDBSCAN) and a dimension reduction technique (UMAP) to assign a label from the tree to these new articles detected as conspiracy theories. We then labeled these groups accordingly to help us match them to the tree. These can lead us to detect new conspiracy theories and expand the tree using computational methods. We successfully generated a tree of conspiracy theories and built a pipeline to detect and categorize conspiracy theories within any text corpora. This pipeline gives us valuable insights through any databases formatted as text.</p>","PeriodicalId":11887,"journal":{"name":"EPJ Data Science","volume":"1 1","pages":""},"PeriodicalIF":2.5000,"publicationDate":"2024-04-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"EPJ Data Science","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1140/epjds/s13688-024-00470-5","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
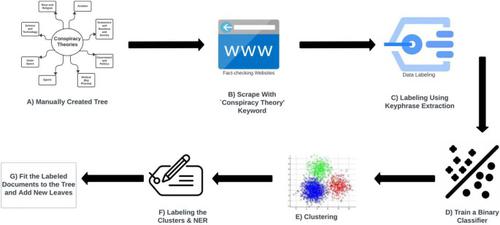
A conspiracy theory (CT) suggests covert groups or powerful individuals secretly manipulate events. Not knowing about existing conspiracy theories could make one more likely to believe them, so this work aims to compile a list of CTs shaped as a tree that is as comprehensive as possible. We began with a manually curated ‘tree’ of CTs from academic papers and Wikipedia. Next, we examined 1769 CT-related articles from four fact-checking websites, focusing on their core content, and used a technique called Keyphrase Extraction to label the documents. This process yielded 769 identified conspiracies, each assigned a label and a family name. The second goal of this project was to detect whether an article is a conspiracy theory, so we built a binary classifier with our labeled dataset. This model uses a transformer-based machine learning technique and is pre-trained on a large corpus called RoBERTa, resulting in an F1 score of 87%. This model helps to identify potential conspiracy theories in new articles. We used a combination of clustering (HDBSCAN) and a dimension reduction technique (UMAP) to assign a label from the tree to these new articles detected as conspiracy theories. We then labeled these groups accordingly to help us match them to the tree. These can lead us to detect new conspiracy theories and expand the tree using computational methods. We successfully generated a tree of conspiracy theories and built a pipeline to detect and categorize conspiracy theories within any text corpora. This pipeline gives us valuable insights through any databases formatted as text.
期刊介绍:
EPJ Data Science covers a broad range of research areas and applications and particularly encourages contributions from techno-socio-economic systems, where it comprises those research lines that now regard the digital “tracks” of human beings as first-order objects for scientific investigation. Topics include, but are not limited to, human behavior, social interaction (including animal societies), economic and financial systems, management and business networks, socio-technical infrastructure, health and environmental systems, the science of science, as well as general risk and crisis scenario forecasting up to and including policy advice.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


