Andre O. Beukers, Silvy H. P. Collin, Ross P. Kempner, Nicholas T. Franklin, Samuel J. Gershman, Kenneth A. Norman
{"title":"Blocked training facilitates learning of multiple schemas","authors":"Andre O. Beukers, Silvy H. P. Collin, Ross P. Kempner, Nicholas T. Franklin, Samuel J. Gershman, Kenneth A. Norman","doi":"10.1038/s44271-024-00079-4","DOIUrl":null,"url":null,"abstract":"We all possess a mental library of schemas that specify how different types of events unfold. How are these schemas acquired? A key challenge is that learning a new schema can catastrophically interfere with old knowledge. One solution to this dilemma is to use interleaved training to learn a single representation that accommodates all schemas. However, another class of models posits that catastrophic interference can be avoided by splitting off new representations when large prediction errors occur. A key differentiating prediction is that, according to splitting models, catastrophic interference can be prevented even under blocked training curricula. We conducted a series of semi-naturalistic experiments and simulations with Bayesian and neural network models to compare the predictions made by the “splitting” versus “non-splitting” hypotheses of schema learning. We found better performance in blocked compared to interleaved curricula, and explain these results using a Bayesian model that incorporates representational splitting in response to large prediction errors. In a follow-up experiment, we validated the model prediction that inserting blocked training early in learning leads to better learning performance than inserting blocked training later in learning. Our results suggest that different learning environments (i.e., curricula) play an important role in shaping schema composition. A Bayesian model incorporating representational splitting explains better memory performance in blocked compared to interleaved learning contexts.","PeriodicalId":501698,"journal":{"name":"Communications Psychology","volume":" ","pages":"1-17"},"PeriodicalIF":0.0000,"publicationDate":"2024-04-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.nature.com/articles/s44271-024-00079-4.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Communications Psychology","FirstCategoryId":"1085","ListUrlMain":"https://www.nature.com/articles/s44271-024-00079-4","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
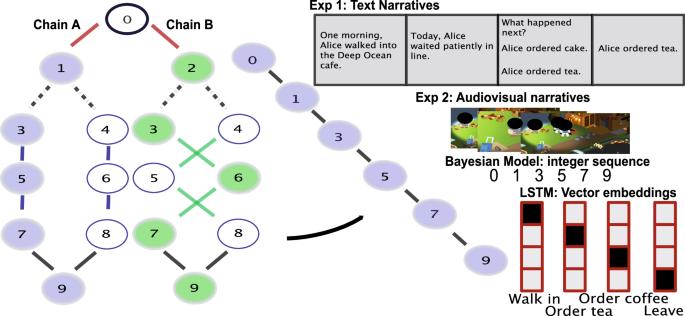
We all possess a mental library of schemas that specify how different types of events unfold. How are these schemas acquired? A key challenge is that learning a new schema can catastrophically interfere with old knowledge. One solution to this dilemma is to use interleaved training to learn a single representation that accommodates all schemas. However, another class of models posits that catastrophic interference can be avoided by splitting off new representations when large prediction errors occur. A key differentiating prediction is that, according to splitting models, catastrophic interference can be prevented even under blocked training curricula. We conducted a series of semi-naturalistic experiments and simulations with Bayesian and neural network models to compare the predictions made by the “splitting” versus “non-splitting” hypotheses of schema learning. We found better performance in blocked compared to interleaved curricula, and explain these results using a Bayesian model that incorporates representational splitting in response to large prediction errors. In a follow-up experiment, we validated the model prediction that inserting blocked training early in learning leads to better learning performance than inserting blocked training later in learning. Our results suggest that different learning environments (i.e., curricula) play an important role in shaping schema composition. A Bayesian model incorporating representational splitting explains better memory performance in blocked compared to interleaved learning contexts.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


