Jing Li, Dezheng Zhang, Yonghong Xie, Aziguli Wulamu, Yao Zhang
{"title":"GP-FMLNet: A feature matrix learning network enhanced by glyph and phonetic information for Chinese sentiment analysis","authors":"Jing Li, Dezheng Zhang, Yonghong Xie, Aziguli Wulamu, Yao Zhang","doi":"10.1049/cit2.12300","DOIUrl":null,"url":null,"abstract":"<p>Sentiment analysis is a fine-grained analysis task that aims to identify the sentiment polarity of a specified sentence. Existing methods in Chinese sentiment analysis tasks only consider sentiment features from a single pole and scale and thus cannot fully exploit and utilise sentiment feature information, making their performance less than ideal. To resolve the problem, the authors propose a new method, GP-FMLNet, that integrates both glyph and phonetic information and design a novel feature matrix learning process for phonetic features with which to model words that have the same pinyin information but different glyph information. Our method solves the problem of misspelling words influencing sentiment polarity prediction results. Specifically, the authors iteratively mine character, glyph, and pinyin features from the input comments sentences. Then, the authors use soft attention and matrix compound modules to model the phonetic features, which empowers their model to keep on zeroing in on the dynamic-setting words in various positions and to dispense with the impacts of the deceptive-setting ones. Experiments on six public datasets prove that the proposed model fully utilises the glyph and phonetic information and improves on the performance of existing Chinese sentiment analysis algorithms.</p>","PeriodicalId":46211,"journal":{"name":"CAAI Transactions on Intelligence Technology","volume":"9 4","pages":"960-972"},"PeriodicalIF":8.4000,"publicationDate":"2024-03-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1049/cit2.12300","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"CAAI Transactions on Intelligence Technology","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1049/cit2.12300","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
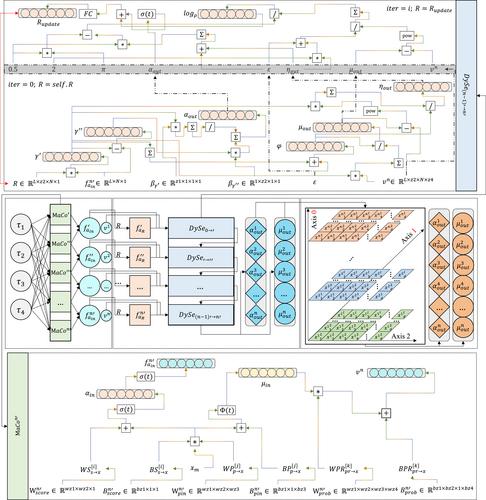
Sentiment analysis is a fine-grained analysis task that aims to identify the sentiment polarity of a specified sentence. Existing methods in Chinese sentiment analysis tasks only consider sentiment features from a single pole and scale and thus cannot fully exploit and utilise sentiment feature information, making their performance less than ideal. To resolve the problem, the authors propose a new method, GP-FMLNet, that integrates both glyph and phonetic information and design a novel feature matrix learning process for phonetic features with which to model words that have the same pinyin information but different glyph information. Our method solves the problem of misspelling words influencing sentiment polarity prediction results. Specifically, the authors iteratively mine character, glyph, and pinyin features from the input comments sentences. Then, the authors use soft attention and matrix compound modules to model the phonetic features, which empowers their model to keep on zeroing in on the dynamic-setting words in various positions and to dispense with the impacts of the deceptive-setting ones. Experiments on six public datasets prove that the proposed model fully utilises the glyph and phonetic information and improves on the performance of existing Chinese sentiment analysis algorithms.
期刊介绍:
CAAI Transactions on Intelligence Technology is a leading venue for original research on the theoretical and experimental aspects of artificial intelligence technology. We are a fully open access journal co-published by the Institution of Engineering and Technology (IET) and the Chinese Association for Artificial Intelligence (CAAI) providing research which is openly accessible to read and share worldwide.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


