Gengxin Liu, Oliver van Kaick, Hui Huang, Ruizhen Hu
{"title":"Active self-training for weakly supervised 3D scene semantic segmentation","authors":"Gengxin Liu, Oliver van Kaick, Hui Huang, Ruizhen Hu","doi":"10.1007/s41095-022-0311-7","DOIUrl":null,"url":null,"abstract":"<p>Since the preparation of labeled data for training semantic segmentation networks of point clouds is a time-consuming process, weakly supervised approaches have been introduced to learn from only a small fraction of data. These methods are typically based on learning with contrastive losses while automatically deriving per-point pseudo-labels from a sparse set of user-annotated labels. In this paper, our key observation is that the selection of which samples to annotate is as important as how these samples are used for training. Thus, we introduce a method for weakly supervised segmentation of 3D scenes that combines self-training with active learning. Active learning selects points for annotation that are likely to result in improvements to the trained model, while self-training makes efficient use of the user-provided labels for learning the model. We demonstrate that our approach leads to an effective method that provides improvements in scene segmentation over previous work and baselines, while requiring only a few user annotations.\n</p>","PeriodicalId":37301,"journal":{"name":"Computational Visual Media","volume":"17 1","pages":""},"PeriodicalIF":18.3000,"publicationDate":"2024-03-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Visual Media","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s41095-022-0311-7","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
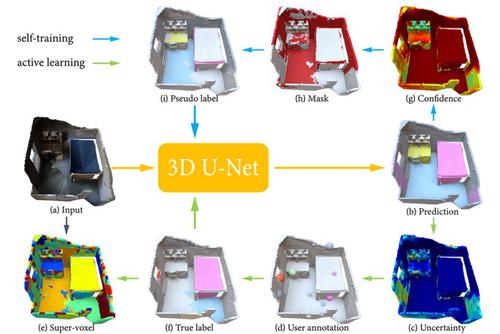
Since the preparation of labeled data for training semantic segmentation networks of point clouds is a time-consuming process, weakly supervised approaches have been introduced to learn from only a small fraction of data. These methods are typically based on learning with contrastive losses while automatically deriving per-point pseudo-labels from a sparse set of user-annotated labels. In this paper, our key observation is that the selection of which samples to annotate is as important as how these samples are used for training. Thus, we introduce a method for weakly supervised segmentation of 3D scenes that combines self-training with active learning. Active learning selects points for annotation that are likely to result in improvements to the trained model, while self-training makes efficient use of the user-provided labels for learning the model. We demonstrate that our approach leads to an effective method that provides improvements in scene segmentation over previous work and baselines, while requiring only a few user annotations.
期刊介绍:
Computational Visual Media is a peer-reviewed open access journal. It publishes original high-quality research papers and significant review articles on novel ideas, methods, and systems relevant to visual media.
Computational Visual Media publishes articles that focus on, but are not limited to, the following areas:
• Editing and composition of visual media
• Geometric computing for images and video
• Geometry modeling and processing
• Machine learning for visual media
• Physically based animation
• Realistic rendering
• Recognition and understanding of visual media
• Visual computing for robotics
• Visualization and visual analytics
Other interdisciplinary research into visual media that combines aspects of computer graphics, computer vision, image and video processing, geometric computing, and machine learning is also within the journal''s scope.
This is an open access journal, published quarterly by Tsinghua University Press and Springer. The open access fees (article-processing charges) are fully sponsored by Tsinghua University, China. Authors can publish in the journal without any additional charges.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


