Davide Boldini, Lukas Friedrich, Daniel Kuhn and Stephan A. Sieber*,
{"title":"Machine Learning Assisted Hit Prioritization for High Throughput Screening in Drug Discovery","authors":"Davide Boldini, Lukas Friedrich, Daniel Kuhn and Stephan A. Sieber*, ","doi":"10.1021/acscentsci.3c01517","DOIUrl":null,"url":null,"abstract":"<p >Efficient prioritization of bioactive compounds from high throughput screening campaigns is a fundamental challenge for accelerating drug development efforts. In this study, we present the first data-driven approach to simultaneously detect assay interferents and prioritize true bioactive compounds. By analyzing the learning dynamics during training of a gradient boosting model on noisy high throughput screening data using a novel formulation of sample influence, we are able to distinguish between compounds exhibiting the desired biological response and those producing assay artifacts. Therefore, our method enables false positive and true positive detection without relying on prior screens or assay interference mechanisms, making it applicable to any high throughput screening campaign. We demonstrate that our approach consistently excludes assay interferents with different mechanisms and prioritizes biologically relevant compounds more efficiently than all tested baselines, including a retrospective case study simulating its use in a real drug discovery campaign. Finally, our tool is extremely computationally efficient, requiring less than 30 s per assay on low-resource hardware. As such, our findings show that our method is an ideal addition to existing false positive detection tools and can be used to guide further pharmacological optimization after high throughput screening campaigns.</p><p >Minimum variance sampling analysis (MVS-A) is a fast machine-learning approach enabling the identification of both true bioactive compounds and false positives in high throughput screening data.</p>","PeriodicalId":10,"journal":{"name":"ACS Central Science","volume":null,"pages":null},"PeriodicalIF":12.7000,"publicationDate":"2024-03-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://pubs.acs.org/doi/epdf/10.1021/acscentsci.3c01517","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"ACS Central Science","FirstCategoryId":"92","ListUrlMain":"https://pubs.acs.org/doi/10.1021/acscentsci.3c01517","RegionNum":1,"RegionCategory":"化学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, MULTIDISCIPLINARY","Score":null,"Total":0}
引用次数: 0
Abstract
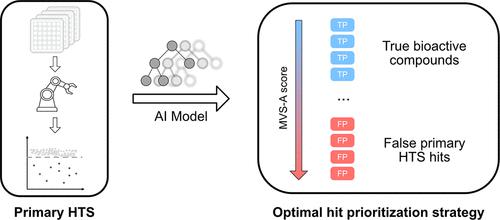
Efficient prioritization of bioactive compounds from high throughput screening campaigns is a fundamental challenge for accelerating drug development efforts. In this study, we present the first data-driven approach to simultaneously detect assay interferents and prioritize true bioactive compounds. By analyzing the learning dynamics during training of a gradient boosting model on noisy high throughput screening data using a novel formulation of sample influence, we are able to distinguish between compounds exhibiting the desired biological response and those producing assay artifacts. Therefore, our method enables false positive and true positive detection without relying on prior screens or assay interference mechanisms, making it applicable to any high throughput screening campaign. We demonstrate that our approach consistently excludes assay interferents with different mechanisms and prioritizes biologically relevant compounds more efficiently than all tested baselines, including a retrospective case study simulating its use in a real drug discovery campaign. Finally, our tool is extremely computationally efficient, requiring less than 30 s per assay on low-resource hardware. As such, our findings show that our method is an ideal addition to existing false positive detection tools and can be used to guide further pharmacological optimization after high throughput screening campaigns.
Minimum variance sampling analysis (MVS-A) is a fast machine-learning approach enabling the identification of both true bioactive compounds and false positives in high throughput screening data.
期刊介绍:
ACS Central Science publishes significant primary reports on research in chemistry and allied fields where chemical approaches are pivotal. As the first fully open-access journal by the American Chemical Society, it covers compelling and important contributions to the broad chemistry and scientific community. "Central science," a term popularized nearly 40 years ago, emphasizes chemistry's central role in connecting physical and life sciences, and fundamental sciences with applied disciplines like medicine and engineering. The journal focuses on exceptional quality articles, addressing advances in fundamental chemistry and interdisciplinary research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


