Distributional ecology: Opening new research windows by addressing aggregation-related puzzles
Abstract
Aim
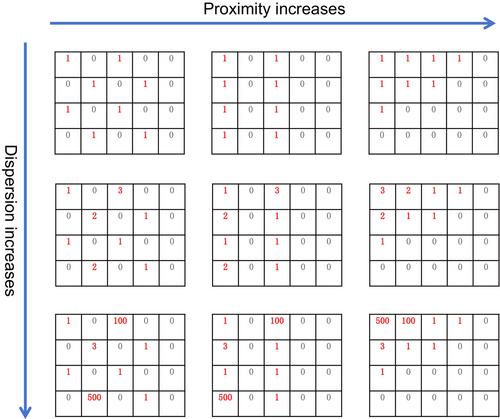
Distribution of species is one of the most elementary but fundamental biodiversity patterns, yet too many puzzles remain unsolved. In most cases, distribution of species is not random, but presents some degree of aggregation. Accordingly, the term ‘distributional aggregation’ is prevailingly used in ecology and evolutionary biology to reflect the non-random distribution characteristic of species in space and time. However, its meanings are multiform and can be decomposed into a variety of components.
Location
Global.
Methods
In this paper, through synthesizing historical literature and comparing relevant meanings of distributional aggregation under different contexts, we summarize the current statistical metrics in detecting and evaluating distributional aggregation that are suitable for different field-survey methods, study models and sampling scales. In particular, we explore the concept under the multi-species setting for which few conceptual advances and statistical methods have been developed.
Results
We propose pure data dispersion and spatiotemporal proximity, as two basic components of distributional aggregation. We further explore three advanced components of distributional aggregation: orthogonal, hierarchical and parallel components that can simultaneously link sampling taxa, sampling sites and sampling methods.
Main Conclusions
We hope the systematic review can serve as a potentially useful primer to ecologists for better understanding and investigating complex and new distributional patterns of biological diversity. We further provide informative guides on developing new statistical methods and metrics. We also discuss useful simulation algorithms for generating diverse distributional aggregation patterns of species, aiming to help ecologists to test and compare the performance of different metrics related to diversity and distribution patterns of species.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


