Suvodeep Majumder, Joymallya Chakraborty, Tim Menzies
{"title":"When less is more: on the value of “co-training” for semi-supervised software defect predictors","authors":"Suvodeep Majumder, Joymallya Chakraborty, Tim Menzies","doi":"10.1007/s10664-023-10418-4","DOIUrl":null,"url":null,"abstract":"<p>Labeling a module defective or non-defective is an expensive task. Hence, there are often limits on how much-labeled data is available for training. Semi-supervised classifiers use far fewer labels for training models. However, there are numerous semi-supervised methods, including self-labeling, co-training, maximal-margin, and graph-based methods, to name a few. Only a handful of these methods have been tested in SE for (e.g.) predicting defects– and even there, those methods have been tested on just a handful of projects. This paper applies a wide range of 55 semi-supervised learners to over 714 projects. We find that semi-supervised “co-training methods” work significantly better than other approaches. Specifically, after labeling, just 2.5% of data, then make predictions that are competitive to those using 100% of the data. That said, co-training needs to be used cautiously since the specific choice of co-training methods needs to be carefully selected based on a user’s specific goals. Also, we warn that a commonly-used co-training method (“multi-view”– where different learners get different sets of columns) does not improve predictions (while adding too much to the run time costs 11 hours vs. 1.8 hours). It is an open question, worthy of future work, to test if these reductions can be seen in other areas of software analytics. To assist with exploring other areas, all the codes used are available at https://github.com/ai-se/Semi-Supervised.</p>","PeriodicalId":11525,"journal":{"name":"Empirical Software Engineering","volume":"27 1","pages":""},"PeriodicalIF":3.5000,"publicationDate":"2024-02-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Empirical Software Engineering","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10664-023-10418-4","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
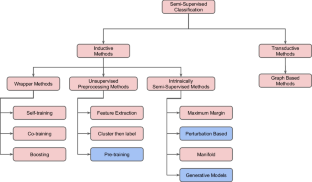
Labeling a module defective or non-defective is an expensive task. Hence, there are often limits on how much-labeled data is available for training. Semi-supervised classifiers use far fewer labels for training models. However, there are numerous semi-supervised methods, including self-labeling, co-training, maximal-margin, and graph-based methods, to name a few. Only a handful of these methods have been tested in SE for (e.g.) predicting defects– and even there, those methods have been tested on just a handful of projects. This paper applies a wide range of 55 semi-supervised learners to over 714 projects. We find that semi-supervised “co-training methods” work significantly better than other approaches. Specifically, after labeling, just 2.5% of data, then make predictions that are competitive to those using 100% of the data. That said, co-training needs to be used cautiously since the specific choice of co-training methods needs to be carefully selected based on a user’s specific goals. Also, we warn that a commonly-used co-training method (“multi-view”– where different learners get different sets of columns) does not improve predictions (while adding too much to the run time costs 11 hours vs. 1.8 hours). It is an open question, worthy of future work, to test if these reductions can be seen in other areas of software analytics. To assist with exploring other areas, all the codes used are available at https://github.com/ai-se/Semi-Supervised.
期刊介绍:
Empirical Software Engineering provides a forum for applied software engineering research with a strong empirical component, and a venue for publishing empirical results relevant to both researchers and practitioners. Empirical studies presented here usually involve the collection and analysis of data and experience that can be used to characterize, evaluate and reveal relationships between software development deliverables, practices, and technologies. Over time, it is expected that such empirical results will form a body of knowledge leading to widely accepted and well-formed theories.
The journal also offers industrial experience reports detailing the application of software technologies - processes, methods, or tools - and their effectiveness in industrial settings.
Empirical Software Engineering promotes the publication of industry-relevant research, to address the significant gap between research and practice.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


