{"title":"A Robust Framework for fraud Detection in Banking using ML and NN","authors":"Astha Vashistha, Anoop Kumar Tiwari, Priyanshi Singh, Paritosh Kumar Yadav, Sudhakar Pandey","doi":"10.1007/s40010-024-00871-1","DOIUrl":null,"url":null,"abstract":"<div><p>Banking fraud is a problem that is becoming more and more serious, along with considerable monetary losses, damage to the bank's brand, loss of client and customer confidence. Fraud identification and prevention are major challenges for many financial organizations, retail firms, and e-commerce companies. Fraud detection is used to both identify and stop fraudsters from obtaining goods or bugs illegally. In the same vein, this research will conduct a feasibility study to determine the best fraud detection strategy. We provide a list of the tried-and-true methods for spotting fraud. To avoid fraud detection, many techniques like Deep Neural Network, Support Vector Machine, Multilayer Perceptron, K-Nearest Neighbors, Random Forest, XG Boost, LGBM, and Decision Tree were used. The dataset was built from 20,000 entries on Kaggle, each having 114 attributes. Before using machine learning and neural network approaches, the dataset is balanced using the Synthetic Minority Over-Sampling Method. Following the analysis of the dataset using a number of methods, it was determined that Random Forest, Decision Tree, XG Boost, and LGBM all had 100% accuracy. This demonstrates that the model outperformed other models by balancing the dataset.</p></div>","PeriodicalId":744,"journal":{"name":"Proceedings of the National Academy of Sciences, India Section A: Physical Sciences","volume":"94 2","pages":"201 - 212"},"PeriodicalIF":0.8000,"publicationDate":"2024-02-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Proceedings of the National Academy of Sciences, India Section A: Physical Sciences","FirstCategoryId":"103","ListUrlMain":"https://link.springer.com/article/10.1007/s40010-024-00871-1","RegionNum":4,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
引用次数: 0
Abstract
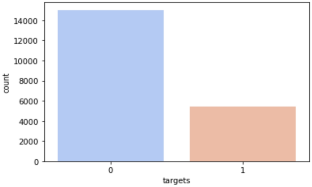
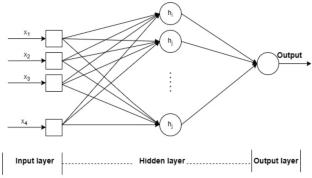
Banking fraud is a problem that is becoming more and more serious, along with considerable monetary losses, damage to the bank's brand, loss of client and customer confidence. Fraud identification and prevention are major challenges for many financial organizations, retail firms, and e-commerce companies. Fraud detection is used to both identify and stop fraudsters from obtaining goods or bugs illegally. In the same vein, this research will conduct a feasibility study to determine the best fraud detection strategy. We provide a list of the tried-and-true methods for spotting fraud. To avoid fraud detection, many techniques like Deep Neural Network, Support Vector Machine, Multilayer Perceptron, K-Nearest Neighbors, Random Forest, XG Boost, LGBM, and Decision Tree were used. The dataset was built from 20,000 entries on Kaggle, each having 114 attributes. Before using machine learning and neural network approaches, the dataset is balanced using the Synthetic Minority Over-Sampling Method. Following the analysis of the dataset using a number of methods, it was determined that Random Forest, Decision Tree, XG Boost, and LGBM all had 100% accuracy. This demonstrates that the model outperformed other models by balancing the dataset.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


