Giovanni Pintore, Eva Almansa, Armando Sanchez, Giorgio Vassena, Enrico Gobbetti
{"title":"Deep panoramic depth prediction and completion for indoor scenes","authors":"Giovanni Pintore, Eva Almansa, Armando Sanchez, Giorgio Vassena, Enrico Gobbetti","doi":"10.1007/s41095-023-0358-0","DOIUrl":null,"url":null,"abstract":"<p>We introduce a novel end-to-end deep-learning solution for rapidly estimating a dense spherical depth map of an indoor environment. Our input is a single equirectangular image registered with a sparse depth map, as provided by a variety of common capture setups. Depth is inferred by an efficient and lightweight single-branch network, which employs a dynamic gating system to process together dense visual data and sparse geometric data. We exploit the characteristics of typical man-made environments to efficiently compress multi-resolution features and find short- and long-range relations among scene parts. Furthermore, we introduce a new augmentation strategy to make the model robust to different types of sparsity, including those generated by various structured light sensors and LiDAR setups. The experimental results demonstrate that our method provides interactive performance and outperforms state-of-the-art solutions in computational efficiency, adaptivity to variable depth sparsity patterns, and prediction accuracy for challenging indoor data, even when trained solely on synthetic data without any fine tuning.\n</p>","PeriodicalId":37301,"journal":{"name":"Computational Visual Media","volume":"3 1","pages":""},"PeriodicalIF":18.3000,"publicationDate":"2024-02-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Visual Media","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s41095-023-0358-0","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
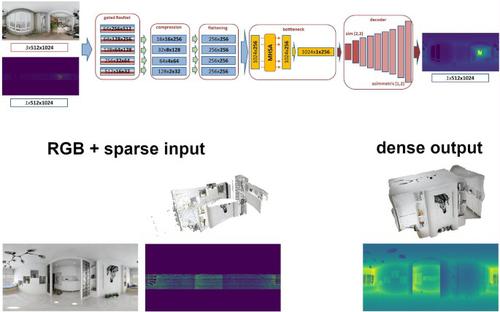
We introduce a novel end-to-end deep-learning solution for rapidly estimating a dense spherical depth map of an indoor environment. Our input is a single equirectangular image registered with a sparse depth map, as provided by a variety of common capture setups. Depth is inferred by an efficient and lightweight single-branch network, which employs a dynamic gating system to process together dense visual data and sparse geometric data. We exploit the characteristics of typical man-made environments to efficiently compress multi-resolution features and find short- and long-range relations among scene parts. Furthermore, we introduce a new augmentation strategy to make the model robust to different types of sparsity, including those generated by various structured light sensors and LiDAR setups. The experimental results demonstrate that our method provides interactive performance and outperforms state-of-the-art solutions in computational efficiency, adaptivity to variable depth sparsity patterns, and prediction accuracy for challenging indoor data, even when trained solely on synthetic data without any fine tuning.
期刊介绍:
Computational Visual Media is a peer-reviewed open access journal. It publishes original high-quality research papers and significant review articles on novel ideas, methods, and systems relevant to visual media.
Computational Visual Media publishes articles that focus on, but are not limited to, the following areas:
• Editing and composition of visual media
• Geometric computing for images and video
• Geometry modeling and processing
• Machine learning for visual media
• Physically based animation
• Realistic rendering
• Recognition and understanding of visual media
• Visual computing for robotics
• Visualization and visual analytics
Other interdisciplinary research into visual media that combines aspects of computer graphics, computer vision, image and video processing, geometric computing, and machine learning is also within the journal''s scope.
This is an open access journal, published quarterly by Tsinghua University Press and Springer. The open access fees (article-processing charges) are fully sponsored by Tsinghua University, China. Authors can publish in the journal without any additional charges.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


