Matthew K Moore, Gillian Whalley, Gregory T Jones, Sean Coffey
{"title":"Use of an ultrasound picture archiving and communication system to answer research questions: Description of data cleaning methods","authors":"Matthew K Moore, Gillian Whalley, Gregory T Jones, Sean Coffey","doi":"10.1002/ajum.12374","DOIUrl":null,"url":null,"abstract":"<div>\n \n \n <section>\n \n <h3> Introduction/Purpose</h3>\n \n <p>Ultrasound picture archiving and communication system (PACS) databases are useful for quality improvement and clinical research but frequently contain free text that is not easily readable. Here, we present a method to extract and clean a semi-structured echocardiography (cardiac ultrasound) PACS database.</p>\n </section>\n \n <section>\n \n <h3> Methods</h3>\n \n <p>Echocardiography studies between 1 January 2010 and 31 December 2018 were extracted using a data mining tool. Numeric variables were recoded with extreme values excluded. Analysis of free text, including descriptions of the heart valves and right and left ventricular size and function, was performed using a rule-based system. Different levels of free text variables were initially identified using commonly used phrases and then iteratively developed. Randomly selected sets of 100 studies were compared to the electronic health record to validate the data cleaning process.</p>\n </section>\n \n <section>\n \n <h3> Results</h3>\n \n <p>The data validation step was performed three times in total, with Cohen's kappa ranging between 0.88 and 1.00 for the final set of data validation across all measures.</p>\n </section>\n \n <section>\n \n <h3> Conclusion</h3>\n \n <p>Free text cleaning of semi-structured PACS databases is possible using freely available open-source software. The accuracy of this method is high, and the resulting dataset can be linked to administrative data to answer research questions. We present a method that could be used to answer clinical questions or to develop quality improvement initiatives.</p>\n </section>\n </div>","PeriodicalId":36517,"journal":{"name":"Australasian Journal of Ultrasound in Medicine","volume":"27 1","pages":"49-55"},"PeriodicalIF":0.0000,"publicationDate":"2024-01-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/ajum.12374","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Australasian Journal of Ultrasound in Medicine","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/ajum.12374","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"Medicine","Score":null,"Total":0}
引用次数: 0
Abstract
Introduction/Purpose
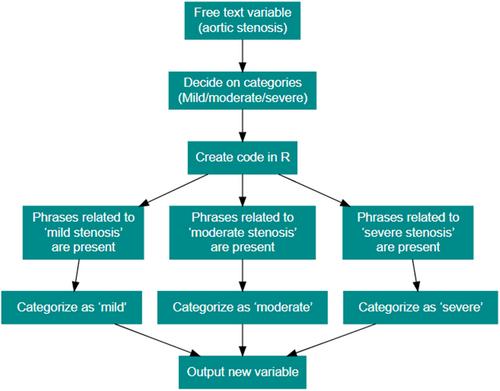
Ultrasound picture archiving and communication system (PACS) databases are useful for quality improvement and clinical research but frequently contain free text that is not easily readable. Here, we present a method to extract and clean a semi-structured echocardiography (cardiac ultrasound) PACS database.
Methods
Echocardiography studies between 1 January 2010 and 31 December 2018 were extracted using a data mining tool. Numeric variables were recoded with extreme values excluded. Analysis of free text, including descriptions of the heart valves and right and left ventricular size and function, was performed using a rule-based system. Different levels of free text variables were initially identified using commonly used phrases and then iteratively developed. Randomly selected sets of 100 studies were compared to the electronic health record to validate the data cleaning process.
Results
The data validation step was performed three times in total, with Cohen's kappa ranging between 0.88 and 1.00 for the final set of data validation across all measures.
Conclusion
Free text cleaning of semi-structured PACS databases is possible using freely available open-source software. The accuracy of this method is high, and the resulting dataset can be linked to administrative data to answer research questions. We present a method that could be used to answer clinical questions or to develop quality improvement initiatives.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


