Kira Wegner-Clemens, George L Malcolm, Sarah Shomstein
{"title":"Predicting attentional allocation in real-world environments: The need to investigate crossmodal semantic guidance.","authors":"Kira Wegner-Clemens, George L Malcolm, Sarah Shomstein","doi":"10.1002/wcs.1675","DOIUrl":null,"url":null,"abstract":"<p><p>Real-world environments are multisensory, meaningful, and highly complex. To parse these environments in a highly efficient manner, a subset of this information must be selected both within and across modalities. However, the bulk of attention research has been conducted within sensory modalities, with a particular focus on vision. Visual attention research has made great strides, with over a century of research methodically identifying the underlying mechanisms that allow us to select critical visual information. Spatial attention, attention to features, and object-based attention have all been studied extensively. More recently, research has established semantics (meaning) as a key component to allocating attention in real-world scenes, with the meaning of an item or environment affecting visual attentional selection. However, a full understanding of how semantic information modulates real-world attention requires studying more than vision in isolation. The world provides semantic information across all senses, but with this extra information comes greater complexity. Here, we summarize visual attention (including semantic-based visual attention), crossmodal attention, and argue for the importance of studying crossmodal semantic guidance of attention. This article is categorized under: Psychology > Attention Psychology > Perception and Psychophysics.</p>","PeriodicalId":47720,"journal":{"name":"Wiley Interdisciplinary Reviews-Cognitive Science","volume":" ","pages":"e1675"},"PeriodicalIF":3.8000,"publicationDate":"2024-05-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Wiley Interdisciplinary Reviews-Cognitive Science","FirstCategoryId":"102","ListUrlMain":"https://doi.org/10.1002/wcs.1675","RegionNum":2,"RegionCategory":"心理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/19 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"PSYCHOLOGY, EXPERIMENTAL","Score":null,"Total":0}
引用次数: 0
Abstract
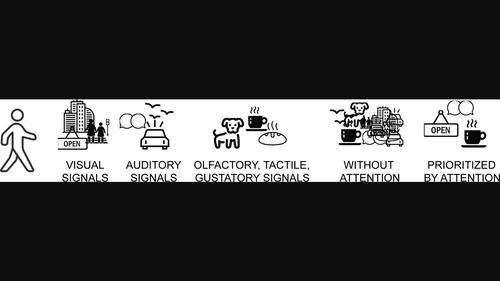
Real-world environments are multisensory, meaningful, and highly complex. To parse these environments in a highly efficient manner, a subset of this information must be selected both within and across modalities. However, the bulk of attention research has been conducted within sensory modalities, with a particular focus on vision. Visual attention research has made great strides, with over a century of research methodically identifying the underlying mechanisms that allow us to select critical visual information. Spatial attention, attention to features, and object-based attention have all been studied extensively. More recently, research has established semantics (meaning) as a key component to allocating attention in real-world scenes, with the meaning of an item or environment affecting visual attentional selection. However, a full understanding of how semantic information modulates real-world attention requires studying more than vision in isolation. The world provides semantic information across all senses, but with this extra information comes greater complexity. Here, we summarize visual attention (including semantic-based visual attention), crossmodal attention, and argue for the importance of studying crossmodal semantic guidance of attention. This article is categorized under: Psychology > Attention Psychology > Perception and Psychophysics.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


