Tohren C. G. Kibbey, Denis M. O'Carroll, Andrew Safulko and Greg Coyle
{"title":"Multi-class machine learning classification of PFAS in environmental water samples: a blinded test of performance on unknowns†","authors":"Tohren C. G. Kibbey, Denis M. O'Carroll, Andrew Safulko and Greg Coyle","doi":"10.1039/D3VA00266G","DOIUrl":null,"url":null,"abstract":"<p >The ability to identify the origin of detected PFAS in environmental samples is of great interest. This work used a blinded test to explore the ability of a recently-developed multiclass classification approach to classify unknown PFAS water samples based on composition. The approach was adapted from previous work to identify similarities between the patterns of unknown samples and classes defined by the compositions of samples from more than one hundred different PFAS data sources, in addition to making an overall assessment of whether PFAS is likely of AFFF or non-AFFF origin. Methods permitting the use of data with different subsets of analyzed PFAS components allowed for the use of a training dataset of more than 13 000 samples from a highly diverse range of sites. For this work, researchers at Brown and Caldwell (BC) provided a set of 252 unknown samples to researchers at The University of Oklahoma (OU) and The University of New South Wales (UNSW) for classification. Unknown samples were provided by clients of BC, and also included a number of artificial sample compositions created to test the ability of a rejection method to identify samples too unlike the training dataset for accurate classification. Unknown samples were de-identified and placed in random order prior to being sent to OU and UNSW researchers. Only after classification results had been sent by OU and UNSW researchers to BC researchers did BC provide the actual sample descriptions to OU and UNSW. Results showed extremely strong performance of the method, both in terms of its ability to identify similarities between unknown samples and samples of known origin, and its ability to make more subtle distinctions between sample origin, such as, for example, recognizing unknown samples from an airport wastewater collection system as being compositionally similar to known samples in another airport wastewater collection system. A rejection algorithm was tested and found to be able to identify artificial sample compositions as different from those in the training dataset, a critical feature of a practical supervised machine learning application, necessary to avoid misclassification of unknown samples that are unlike those in the training dataset.</p>","PeriodicalId":72941,"journal":{"name":"Environmental science. Advances","volume":" 3","pages":" 366-382"},"PeriodicalIF":3.5000,"publicationDate":"2024-01-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://pubs.rsc.org/en/content/articlepdf/2024/va/d3va00266g?page=search","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Environmental science. Advances","FirstCategoryId":"1085","ListUrlMain":"https://pubs.rsc.org/en/content/articlelanding/2024/va/d3va00266g","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"ENGINEERING, ENVIRONMENTAL","Score":null,"Total":0}
引用次数: 0
Abstract
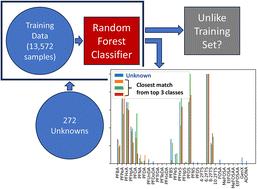
The ability to identify the origin of detected PFAS in environmental samples is of great interest. This work used a blinded test to explore the ability of a recently-developed multiclass classification approach to classify unknown PFAS water samples based on composition. The approach was adapted from previous work to identify similarities between the patterns of unknown samples and classes defined by the compositions of samples from more than one hundred different PFAS data sources, in addition to making an overall assessment of whether PFAS is likely of AFFF or non-AFFF origin. Methods permitting the use of data with different subsets of analyzed PFAS components allowed for the use of a training dataset of more than 13 000 samples from a highly diverse range of sites. For this work, researchers at Brown and Caldwell (BC) provided a set of 252 unknown samples to researchers at The University of Oklahoma (OU) and The University of New South Wales (UNSW) for classification. Unknown samples were provided by clients of BC, and also included a number of artificial sample compositions created to test the ability of a rejection method to identify samples too unlike the training dataset for accurate classification. Unknown samples were de-identified and placed in random order prior to being sent to OU and UNSW researchers. Only after classification results had been sent by OU and UNSW researchers to BC researchers did BC provide the actual sample descriptions to OU and UNSW. Results showed extremely strong performance of the method, both in terms of its ability to identify similarities between unknown samples and samples of known origin, and its ability to make more subtle distinctions between sample origin, such as, for example, recognizing unknown samples from an airport wastewater collection system as being compositionally similar to known samples in another airport wastewater collection system. A rejection algorithm was tested and found to be able to identify artificial sample compositions as different from those in the training dataset, a critical feature of a practical supervised machine learning application, necessary to avoid misclassification of unknown samples that are unlike those in the training dataset.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


