{"title":"Precision enzyme discovery through targeted mining of metagenomic data","authors":"Shohreh Ariaeenejad, Javad Gharechahi, Mehdi Foroozandeh Shahraki, Fereshteh Fallah Atanaki, Jian-Lin Han, Xue-Zhi Ding, Falk Hildebrand, Mohammad Bahram, Kaveh Kavousi, Ghasem Hosseini Salekdeh","doi":"10.1007/s13659-023-00426-8","DOIUrl":null,"url":null,"abstract":"<div><p>Metagenomics has opened new avenues for exploring the genetic potential of uncultured microorganisms, which may serve as promising sources of enzymes and natural products for industrial applications. Identifying enzymes with improved catalytic properties from the vast amount of available metagenomic data poses a significant challenge that demands the development of novel computational and functional screening tools. The catalytic properties of all enzymes are primarily dictated by their structures, which are predominantly determined by their amino acid sequences. However, this aspect has not been fully considered in the enzyme bioprospecting processes. With the accumulating number of available enzyme sequences and the increasing demand for discovering novel biocatalysts, structural and functional modeling can be employed to identify potential enzymes with novel catalytic properties. Recent efforts to discover new polysaccharide-degrading enzymes from rumen metagenome data using homology-based searches and machine learning-based models have shown significant promise. Here, we will explore various computational approaches that can be employed to screen and shortlist metagenome-derived enzymes as potential biocatalyst candidates, in conjunction with the wet lab analytical methods traditionally used for enzyme characterization.</p></div>","PeriodicalId":718,"journal":{"name":"Natural Products and Bioprospecting","volume":"14 1","pages":""},"PeriodicalIF":4.8000,"publicationDate":"2024-01-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10781932/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Natural Products and Bioprospecting","FirstCategoryId":"92","ListUrlMain":"https://link.springer.com/article/10.1007/s13659-023-00426-8","RegionNum":3,"RegionCategory":"化学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, MEDICINAL","Score":null,"Total":0}
引用次数: 0
Abstract
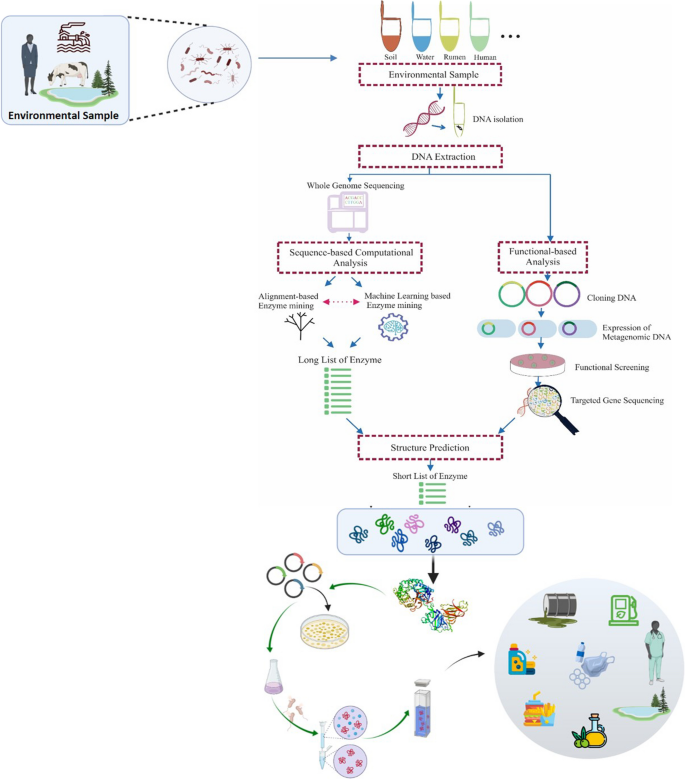
Metagenomics has opened new avenues for exploring the genetic potential of uncultured microorganisms, which may serve as promising sources of enzymes and natural products for industrial applications. Identifying enzymes with improved catalytic properties from the vast amount of available metagenomic data poses a significant challenge that demands the development of novel computational and functional screening tools. The catalytic properties of all enzymes are primarily dictated by their structures, which are predominantly determined by their amino acid sequences. However, this aspect has not been fully considered in the enzyme bioprospecting processes. With the accumulating number of available enzyme sequences and the increasing demand for discovering novel biocatalysts, structural and functional modeling can be employed to identify potential enzymes with novel catalytic properties. Recent efforts to discover new polysaccharide-degrading enzymes from rumen metagenome data using homology-based searches and machine learning-based models have shown significant promise. Here, we will explore various computational approaches that can be employed to screen and shortlist metagenome-derived enzymes as potential biocatalyst candidates, in conjunction with the wet lab analytical methods traditionally used for enzyme characterization.
期刊介绍:
Natural Products and Bioprospecting serves as an international forum for essential research on natural products and focuses on, but is not limited to, the following aspects:
Natural products: isolation and structure elucidation
Natural products: synthesis
Biological evaluation of biologically active natural products
Bioorganic and medicinal chemistry
Biosynthesis and microbiological transformation
Fermentation and plant tissue cultures
Bioprospecting of natural products from natural resources
All research articles published in this journal have undergone rigorous peer review. In addition to original research articles, Natural Products and Bioprospecting publishes reviews and short communications, aiming to rapidly disseminate the research results of timely interest, and comprehensive reviews of emerging topics in all the areas of natural products. It is also an open access journal, which provides free access to its articles to anyone, anywhere.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


