Yuantian Huang, Satoshi Iizuka, Edgar Simo-Serra, Kazuhiro Fukui
{"title":"Controllable multi-domain semantic artwork synthesis","authors":"Yuantian Huang, Satoshi Iizuka, Edgar Simo-Serra, Kazuhiro Fukui","doi":"10.1007/s41095-023-0356-2","DOIUrl":null,"url":null,"abstract":"<p>We present a novel framework for the multi-domain synthesis of artworks from semantic layouts. One of the main limitations of this challenging task is the lack of publicly available segmentation datasets for art synthesis. To address this problem, we propose a dataset called <i>ArtSem</i> that contains 40,000 images of artwork from four different domains, with their corresponding semantic label maps. We first extracted semantic maps from landscape photography and used a conditional generative adversarial network (GAN)-based approach for generating high-quality artwork from semantic maps without requiring paired training data. Furthermore, we propose an artwork-synthesis model using domain-dependent variational encoders for high-quality multi-domain synthesis. Subsequently, the model was improved and complemented with a simple but effective normalization method based on jointly normalizing semantics and style, which we call spatially style-adaptive normalization (SSTAN). Compared to the previous methods, which only take semantic layout as the input, our model jointly learns style and semantic information representation, improving the generation quality of artistic images. These results indicate that our model learned to separate the domains in the latent space. Thus, we can perform fine-grained control of the synthesized artwork by identifying hyperplanes that separate the different domains. Moreover, by combining the proposed dataset and approach, we generated user-controllable artworks of higher quality than that of existing approaches, as corroborated by quantitative metrics and a user study.\n</p>","PeriodicalId":37301,"journal":{"name":"Computational Visual Media","volume":"21 1","pages":""},"PeriodicalIF":18.3000,"publicationDate":"2024-01-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Visual Media","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s41095-023-0356-2","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
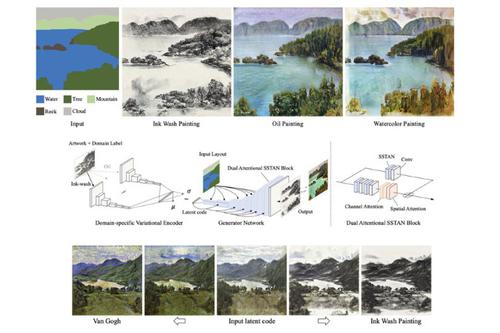
We present a novel framework for the multi-domain synthesis of artworks from semantic layouts. One of the main limitations of this challenging task is the lack of publicly available segmentation datasets for art synthesis. To address this problem, we propose a dataset called ArtSem that contains 40,000 images of artwork from four different domains, with their corresponding semantic label maps. We first extracted semantic maps from landscape photography and used a conditional generative adversarial network (GAN)-based approach for generating high-quality artwork from semantic maps without requiring paired training data. Furthermore, we propose an artwork-synthesis model using domain-dependent variational encoders for high-quality multi-domain synthesis. Subsequently, the model was improved and complemented with a simple but effective normalization method based on jointly normalizing semantics and style, which we call spatially style-adaptive normalization (SSTAN). Compared to the previous methods, which only take semantic layout as the input, our model jointly learns style and semantic information representation, improving the generation quality of artistic images. These results indicate that our model learned to separate the domains in the latent space. Thus, we can perform fine-grained control of the synthesized artwork by identifying hyperplanes that separate the different domains. Moreover, by combining the proposed dataset and approach, we generated user-controllable artworks of higher quality than that of existing approaches, as corroborated by quantitative metrics and a user study.
期刊介绍:
Computational Visual Media is a peer-reviewed open access journal. It publishes original high-quality research papers and significant review articles on novel ideas, methods, and systems relevant to visual media.
Computational Visual Media publishes articles that focus on, but are not limited to, the following areas:
• Editing and composition of visual media
• Geometric computing for images and video
• Geometry modeling and processing
• Machine learning for visual media
• Physically based animation
• Realistic rendering
• Recognition and understanding of visual media
• Visual computing for robotics
• Visualization and visual analytics
Other interdisciplinary research into visual media that combines aspects of computer graphics, computer vision, image and video processing, geometric computing, and machine learning is also within the journal''s scope.
This is an open access journal, published quarterly by Tsinghua University Press and Springer. The open access fees (article-processing charges) are fully sponsored by Tsinghua University, China. Authors can publish in the journal without any additional charges.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


