{"title":"MusicFace: Music-driven expressive singing face synthesis","authors":"Pengfei Liu, Wenjin Deng, Hengda Li, Jintai Wang, Yinglin Zheng, Yiwei Ding, Xiaohu Guo, Ming Zeng","doi":"10.1007/s41095-023-0343-7","DOIUrl":null,"url":null,"abstract":"<p>It remains an interesting and challenging problem to synthesize a vivid and realistic singing face driven by music. In this paper, we present a method for this task with natural motions for the lips, facial expression, head pose, and eyes. Due to the coupling of mixed information for the human voice and backing music in common music audio signals, we design a decouple-and-fuse strategy to tackle the challenge. We first decompose the input music audio into a human voice stream and a backing music stream. Due to the implicit and complicated correlation between the two-stream input signals and the dynamics of the facial expressions, head motions, and eye states, we model their relationship with an attention scheme, where the effects of the two streams are fused seamlessly. Furthermore, to improve the expressivenes of the generated results, we decompose head movement generation in terms of speed and direction, and decompose eye state generation into short-term blinking and long-term eye closing, modeling them separately. We have also built a novel dataset, SingingFace, to support training and evaluation of models for this task, including future work on this topic. Extensive experiments and a user study show that our proposed method is capable of synthesizing vivid singing faces, qualitatively and quantitatively better than the prior state-of-the-art.\n</p>","PeriodicalId":37301,"journal":{"name":"Computational Visual Media","volume":"47 1","pages":""},"PeriodicalIF":18.3000,"publicationDate":"2023-11-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Visual Media","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s41095-023-0343-7","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
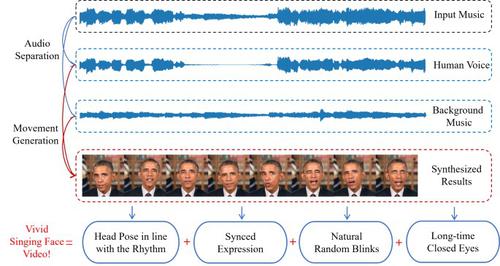
It remains an interesting and challenging problem to synthesize a vivid and realistic singing face driven by music. In this paper, we present a method for this task with natural motions for the lips, facial expression, head pose, and eyes. Due to the coupling of mixed information for the human voice and backing music in common music audio signals, we design a decouple-and-fuse strategy to tackle the challenge. We first decompose the input music audio into a human voice stream and a backing music stream. Due to the implicit and complicated correlation between the two-stream input signals and the dynamics of the facial expressions, head motions, and eye states, we model their relationship with an attention scheme, where the effects of the two streams are fused seamlessly. Furthermore, to improve the expressivenes of the generated results, we decompose head movement generation in terms of speed and direction, and decompose eye state generation into short-term blinking and long-term eye closing, modeling them separately. We have also built a novel dataset, SingingFace, to support training and evaluation of models for this task, including future work on this topic. Extensive experiments and a user study show that our proposed method is capable of synthesizing vivid singing faces, qualitatively and quantitatively better than the prior state-of-the-art.
期刊介绍:
Computational Visual Media is a peer-reviewed open access journal. It publishes original high-quality research papers and significant review articles on novel ideas, methods, and systems relevant to visual media.
Computational Visual Media publishes articles that focus on, but are not limited to, the following areas:
• Editing and composition of visual media
• Geometric computing for images and video
• Geometry modeling and processing
• Machine learning for visual media
• Physically based animation
• Realistic rendering
• Recognition and understanding of visual media
• Visual computing for robotics
• Visualization and visual analytics
Other interdisciplinary research into visual media that combines aspects of computer graphics, computer vision, image and video processing, geometric computing, and machine learning is also within the journal''s scope.
This is an open access journal, published quarterly by Tsinghua University Press and Springer. The open access fees (article-processing charges) are fully sponsored by Tsinghua University, China. Authors can publish in the journal without any additional charges.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


