{"title":"Performance of large language models at the MRCS Part A: a tool for medical education?","authors":"A Yiu, K Lam","doi":"10.1308/rcsann.2023.0085","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>The Intercollegiate Membership of the Royal College of Surgeons examination (MRCS) Part A assesses generic surgical sciences and applied knowledge using 300 multiple-choice Single Best Answer items. Large Language Models (LLMs) are trained on vast amounts of text to generate natural language outputs, and applications in healthcare and medical education are rising.</p><p><strong>Methods: </strong>Two LLMs, ChatGPT (OpenAI) and Bard (Google AI), were tested using 300 questions from a popular MRCS Part A question bank without/with need for justification (NJ/J). LLM outputs were scored according to accuracy, concordance and insight.</p><p><strong>Results: </strong>ChatGPT achieved 85.7%/84.3% accuracy for NJ/J encodings. Bard achieved 64%/64.3% accuracy for NJ/J encodings. ChatGPT and Bard displayed high levels of concordance for NJ (95.3%; 81.7%) and J (93.7%; 79.7%) encodings, respectively. ChatGPT and Bard provided an insightful statement in >98% and >86% outputs, respectively.</p><p><strong>Discussion: </strong>This study demonstrates that ChatGPT achieves passing-level accuracy at MRCS Part A, and both LLMs achieve high concordance and provide insightful responses to test questions. Instances of clinically inappropriate or inaccurate decision-making, incomplete appreciation of nuanced clinical scenarios and utilisation of out-of-date guidance was, however, noted. LLMs are accessible and time-efficient tools, access vast clinical knowledge, and may reduce the emphasis on factual recall in medical education and assessment.</p><p><strong>Conclusion: </strong>ChatGPT achieves passing-level accuracy for MRCS Part A with concordant and insightful outputs. Future applications of LLMs in healthcare must be cautious of hallucinations and incorrect reasoning but have the potential to develop AI-supported clinicians.</p>","PeriodicalId":8088,"journal":{"name":"Annals of the Royal College of Surgeons of England","volume":" ","pages":"434-440"},"PeriodicalIF":1.7000,"publicationDate":"2025-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12208737/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Annals of the Royal College of Surgeons of England","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1308/rcsann.2023.0085","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/12/1 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"SURGERY","Score":null,"Total":0}
引用次数: 0
Abstract
Introduction: The Intercollegiate Membership of the Royal College of Surgeons examination (MRCS) Part A assesses generic surgical sciences and applied knowledge using 300 multiple-choice Single Best Answer items. Large Language Models (LLMs) are trained on vast amounts of text to generate natural language outputs, and applications in healthcare and medical education are rising.
Methods: Two LLMs, ChatGPT (OpenAI) and Bard (Google AI), were tested using 300 questions from a popular MRCS Part A question bank without/with need for justification (NJ/J). LLM outputs were scored according to accuracy, concordance and insight.
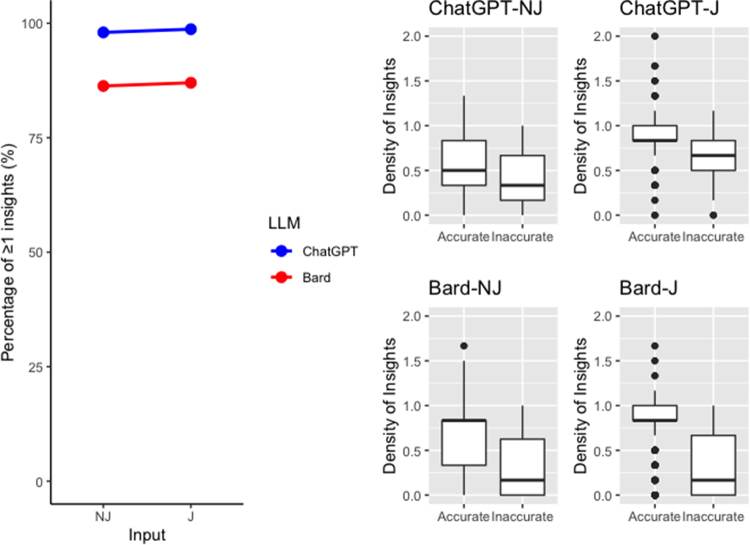
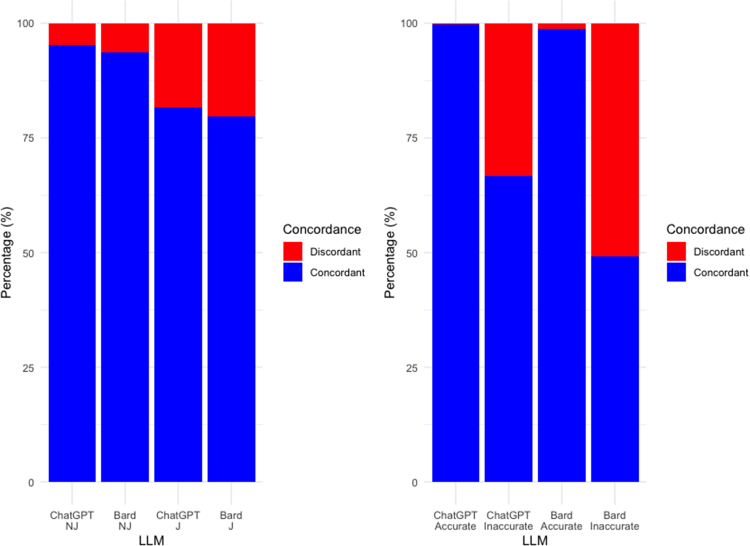
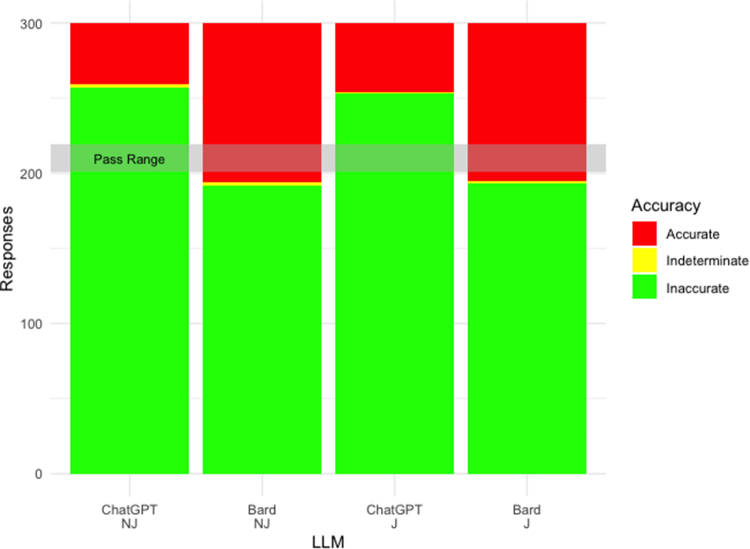
Results: ChatGPT achieved 85.7%/84.3% accuracy for NJ/J encodings. Bard achieved 64%/64.3% accuracy for NJ/J encodings. ChatGPT and Bard displayed high levels of concordance for NJ (95.3%; 81.7%) and J (93.7%; 79.7%) encodings, respectively. ChatGPT and Bard provided an insightful statement in >98% and >86% outputs, respectively.
Discussion: This study demonstrates that ChatGPT achieves passing-level accuracy at MRCS Part A, and both LLMs achieve high concordance and provide insightful responses to test questions. Instances of clinically inappropriate or inaccurate decision-making, incomplete appreciation of nuanced clinical scenarios and utilisation of out-of-date guidance was, however, noted. LLMs are accessible and time-efficient tools, access vast clinical knowledge, and may reduce the emphasis on factual recall in medical education and assessment.
Conclusion: ChatGPT achieves passing-level accuracy for MRCS Part A with concordant and insightful outputs. Future applications of LLMs in healthcare must be cautious of hallucinations and incorrect reasoning but have the potential to develop AI-supported clinicians.
简介:英国皇家外科医师学会校际会员资格考试(MRCS) A部分通过300个单项最佳答案,评估通用外科科学和应用知识。大型语言模型(llm)在大量文本上进行训练以生成自然语言输出,并且在医疗保健和医学教育中的应用正在增加。方法:两个法学硕士,ChatGPT (OpenAI)和Bard (Google AI),使用来自流行的MRCS Part a题库的300个问题进行测试,无需/不需要证明(NJ/J)。根据准确性、一致性和洞察力对LLM输出进行评分。结果:ChatGPT对NJ/J编码的准确率分别为85.7%/84.3%。巴德对NJ/J编码的准确率达到64%/64.3%。ChatGPT和Bard在NJ上显示出高度的一致性(95.3%;81.7%), J (93.7%);79.7%)编码。ChatGPT和Bard分别在>98%和>86%的输出中提供了深刻的陈述。讨论:本研究表明,ChatGPT在MRCS Part A中达到了及格水平的准确性,两个llm都达到了很高的一致性,并对测试问题提供了深刻的回答。然而,注意到临床上不适当或不准确的决策,对细微临床情况的不完全理解以及使用过时的指南的情况。法学硕士是一种方便快捷的工具,可以获得大量的临床知识,并可能减少医学教育和评估中对事实回忆的强调。结论:ChatGPT对MRCS Part A的准确度达到了及格水平,输出结果一致、深刻。法学硕士在医疗保健领域的未来应用必须警惕幻觉和错误的推理,但有可能发展人工智能支持的临床医生。
期刊介绍:
The Annals of The Royal College of Surgeons of England is the official scholarly research journal of the Royal College of Surgeons and is published eight times a year in January, February, March, April, May, July, September and November.
The main aim of the journal is to publish high-quality, peer-reviewed papers that relate to all branches of surgery. The Annals also includes letters and comments, a regular technical section, controversial topics, CORESS feedback and book reviews. The editorial board is composed of experts from all the surgical specialties.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


