Web-Based Application Based on Human-in-the-Loop Deep Learning for Deidentifying Free-Text Data in Electronic Medical Records: Development and Usability Study.
Leibo Liu, Oscar Perez-Concha, Anthony Nguyen, Vicki Bennett, Victoria Blake, Blanca Gallego, Louisa Jorm
{"title":"Web-Based Application Based on Human-in-the-Loop Deep Learning for Deidentifying Free-Text Data in Electronic Medical Records: Development and Usability Study.","authors":"Leibo Liu, Oscar Perez-Concha, Anthony Nguyen, Vicki Bennett, Victoria Blake, Blanca Gallego, Louisa Jorm","doi":"10.2196/46322","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The narrative free-text data in electronic medical records (EMRs) contain valuable clinical information for analysis and research to inform better patient care. However, the release of free text for secondary use is hindered by concerns surrounding personally identifiable information (PII), as protecting individuals' privacy is paramount. Therefore, it is necessary to deidentify free text to remove PII. Manual deidentification is a time-consuming and labor-intensive process. Numerous automated deidentification approaches and systems have been attempted to overcome this challenge over the past decade.</p><p><strong>Objective: </strong>We sought to develop an accurate, web-based system deidentifying free text (DEFT), which can be readily and easily adopted in real-world settings for deidentification of free text in EMRs. The system has several key features including a simple and task-focused web user interface, customized PII types, use of a state-of-the-art deep learning model for tagging PII from free text, preannotation by an interactive learning loop, rapid manual annotation with autosave, support for project management and team collaboration, user access control, and central data storage.</p><p><strong>Methods: </strong>DEFT comprises frontend and backend modules and communicates with central data storage through a filesystem path access. The frontend web user interface provides end users with a user-friendly workspace for managing and annotating free text. The backend module processes the requests from the frontend and performs relevant persistence operations. DEFT manages the deidentification workflow as a project, which can contain one or more data sets. Customized PII types and user access control can also be configured. The deep learning model is based on a Bidirectional Long Short-Term Memory-Conditional Random Field (BiLSTM-CRF) with RoBERTa as the word embedding layer. The interactive learning loop is further integrated into DEFT to speed up the deidentification process and increase its performance over time.</p><p><strong>Results: </strong>DEFT has many advantages over existing deidentification systems in terms of its support for project management, user access control, data management, and an interactive learning process. Experimental results from DEFT on the 2014 i2b2 data set obtained the highest performance compared to 5 benchmark models in terms of microaverage strict entity-level recall and F<sub>1</sub>-scores of 0.9563 and 0.9627, respectively. In a real-world use case of deidentifying clinical notes, extracted from 1 referral hospital in Sydney, New South Wales, Australia, DEFT achieved a high microaverage strict entity-level F<sub>1</sub>-score of 0.9507 on a corpus of 600 annotated clinical notes. Moreover, the manual annotation process with preannotation demonstrated a 43% increase in work efficiency compared to the process without preannotation.</p><p><strong>Conclusions: </strong>DEFT is designed for health domain researchers and data custodians to easily deidentify free text in EMRs. DEFT supports an interactive learning loop and end users with minimal technical knowledge can perform the deidentification work with only a shallow learning curve.</p>","PeriodicalId":51757,"journal":{"name":"Interactive Journal of Medical Research","volume":null,"pages":null},"PeriodicalIF":1.9000,"publicationDate":"2023-08-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10492176/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Interactive Journal of Medical Research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/46322","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MEDICINE, RESEARCH & EXPERIMENTAL","Score":null,"Total":0}
引用次数: 0
Abstract
Background: The narrative free-text data in electronic medical records (EMRs) contain valuable clinical information for analysis and research to inform better patient care. However, the release of free text for secondary use is hindered by concerns surrounding personally identifiable information (PII), as protecting individuals' privacy is paramount. Therefore, it is necessary to deidentify free text to remove PII. Manual deidentification is a time-consuming and labor-intensive process. Numerous automated deidentification approaches and systems have been attempted to overcome this challenge over the past decade.
Objective: We sought to develop an accurate, web-based system deidentifying free text (DEFT), which can be readily and easily adopted in real-world settings for deidentification of free text in EMRs. The system has several key features including a simple and task-focused web user interface, customized PII types, use of a state-of-the-art deep learning model for tagging PII from free text, preannotation by an interactive learning loop, rapid manual annotation with autosave, support for project management and team collaboration, user access control, and central data storage.
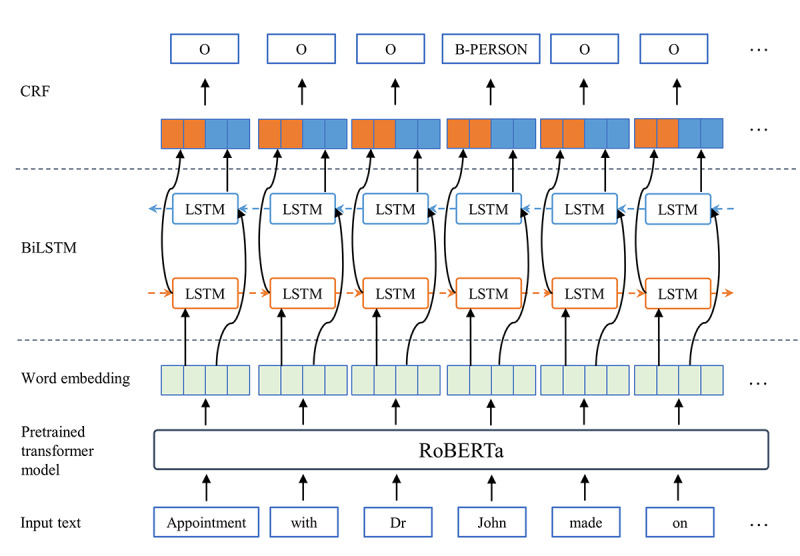
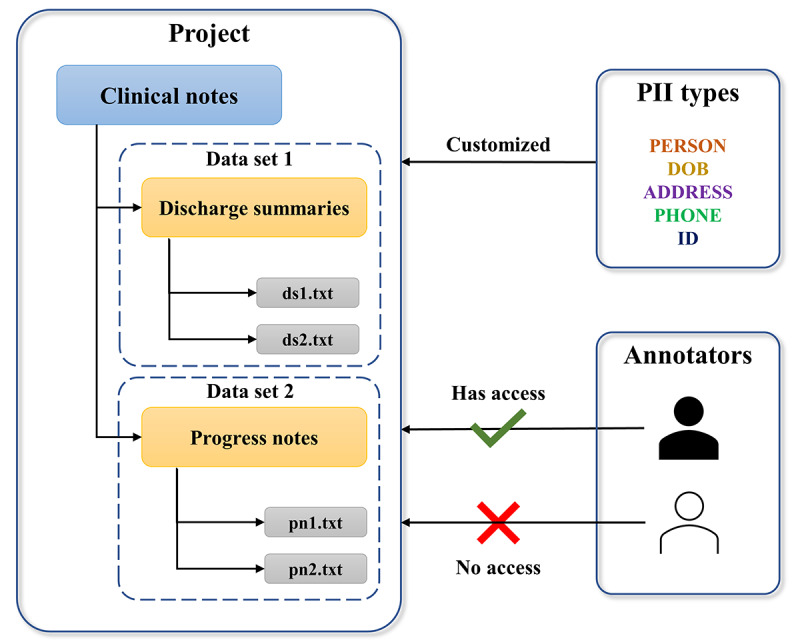
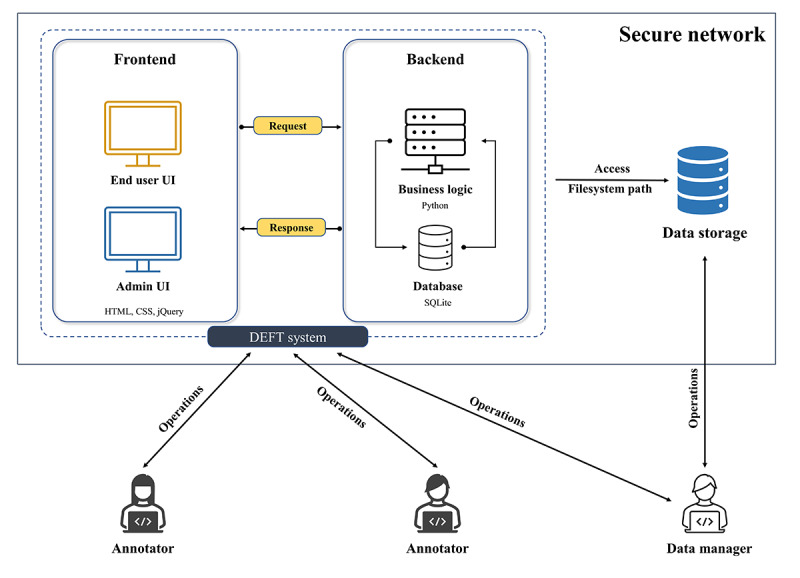
Methods: DEFT comprises frontend and backend modules and communicates with central data storage through a filesystem path access. The frontend web user interface provides end users with a user-friendly workspace for managing and annotating free text. The backend module processes the requests from the frontend and performs relevant persistence operations. DEFT manages the deidentification workflow as a project, which can contain one or more data sets. Customized PII types and user access control can also be configured. The deep learning model is based on a Bidirectional Long Short-Term Memory-Conditional Random Field (BiLSTM-CRF) with RoBERTa as the word embedding layer. The interactive learning loop is further integrated into DEFT to speed up the deidentification process and increase its performance over time.
Results: DEFT has many advantages over existing deidentification systems in terms of its support for project management, user access control, data management, and an interactive learning process. Experimental results from DEFT on the 2014 i2b2 data set obtained the highest performance compared to 5 benchmark models in terms of microaverage strict entity-level recall and F1-scores of 0.9563 and 0.9627, respectively. In a real-world use case of deidentifying clinical notes, extracted from 1 referral hospital in Sydney, New South Wales, Australia, DEFT achieved a high microaverage strict entity-level F1-score of 0.9507 on a corpus of 600 annotated clinical notes. Moreover, the manual annotation process with preannotation demonstrated a 43% increase in work efficiency compared to the process without preannotation.
Conclusions: DEFT is designed for health domain researchers and data custodians to easily deidentify free text in EMRs. DEFT supports an interactive learning loop and end users with minimal technical knowledge can perform the deidentification work with only a shallow learning curve.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


