James T Anibal, Adam J Landa, Nguyen T T Hang, Miranda J Song, Alec K Peltekian, Ashley Shin, Hannah B Huth, Lindsey A Hazen, Anna S Christou, Jocelyne Rivera, Robert A Morhard, Ulas Bagci, Ming Li, Yael Bensoussan, David A Clifton, Bradford J Wood
{"title":"Omicron detection with large language models and YouTube audio data.","authors":"James T Anibal, Adam J Landa, Nguyen T T Hang, Miranda J Song, Alec K Peltekian, Ashley Shin, Hannah B Huth, Lindsey A Hazen, Anna S Christou, Jocelyne Rivera, Robert A Morhard, Ulas Bagci, Ming Li, Yael Bensoussan, David A Clifton, Bradford J Wood","doi":"10.1101/2022.09.13.22279673","DOIUrl":null,"url":null,"abstract":"<p><p>Publicly available audio data presents a unique opportunity for the development of digital health technologies with large language models (LLMs). In this study, YouTube was mined to collect audio data from individuals with self-declared positive COVID-19 tests as well as those with other upper respiratory infections (URI) and healthy subjects discussing a diverse range of topics. The resulting dataset was transcribed with the Whisper model and used to assess the capacity of LLMs for detecting self-reported COVID-19 cases and performing variant classification. Following prompt optimization, LLMs achieved accuracies of 0.89, 0.97, respectively, in the tasks of identifying self-reported COVID-19 cases and other respiratory illnesses. The model also obtained a mean accuracy of 0.77 at identifying the variant of self-reported COVID-19 cases using only symptoms and other health-related factors described in the YouTube videos. In comparison with past studies, which used scripted, standardized voice samples to capture biomarkers, this study focused on extracting meaningful information from public online audio data. This work introduced novel design paradigms for pandemic management tools, showing the potential of audio data in clinical and public health applications.</p>","PeriodicalId":18659,"journal":{"name":"medRxiv : the preprint server for health sciences","volume":" ","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-03-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9516853/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"medRxiv : the preprint server for health sciences","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1101/2022.09.13.22279673","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
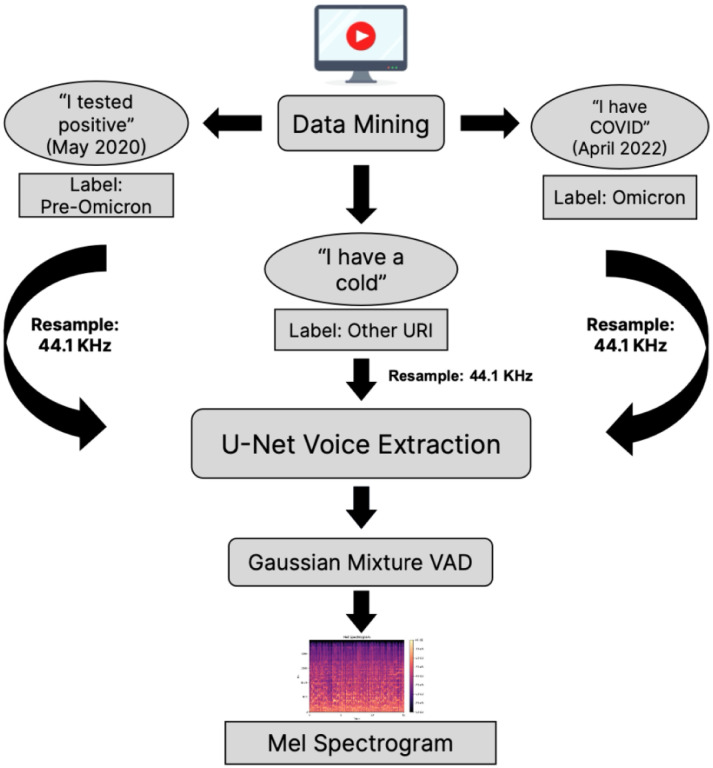
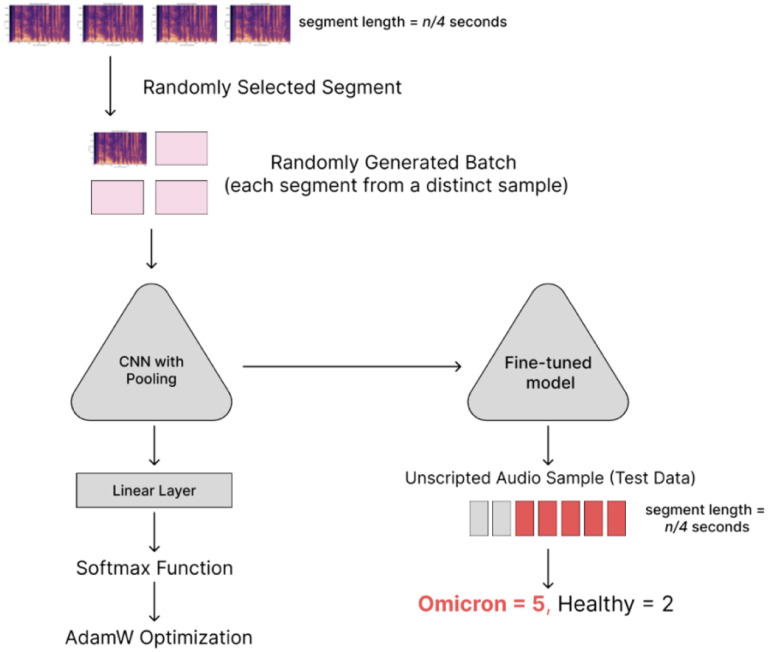
Publicly available audio data presents a unique opportunity for the development of digital health technologies with large language models (LLMs). In this study, YouTube was mined to collect audio data from individuals with self-declared positive COVID-19 tests as well as those with other upper respiratory infections (URI) and healthy subjects discussing a diverse range of topics. The resulting dataset was transcribed with the Whisper model and used to assess the capacity of LLMs for detecting self-reported COVID-19 cases and performing variant classification. Following prompt optimization, LLMs achieved accuracies of 0.89, 0.97, respectively, in the tasks of identifying self-reported COVID-19 cases and other respiratory illnesses. The model also obtained a mean accuracy of 0.77 at identifying the variant of self-reported COVID-19 cases using only symptoms and other health-related factors described in the YouTube videos. In comparison with past studies, which used scripted, standardized voice samples to capture biomarkers, this study focused on extracting meaningful information from public online audio data. This work introduced novel design paradigms for pandemic management tools, showing the potential of audio data in clinical and public health applications.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


