{"title":"Effect of data size on tooth numbering performance via artificial intelligence using panoramic radiographs.","authors":"Semih Gülüm, Seçilay Kutal, Kader Cesur Aydin, Gazi Akgün, Aleyna Akdağ","doi":"10.1007/s11282-023-00689-4","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>This study aims to investigate the effect of number of data on model performance, for the detection of tooth numbering problem on dental panoramic radiographs, with the help of image processing and deep learning algorithms.</p><p><strong>Study design: </strong>The data set consists of 3000 anonymous dental panoramic X-rays of adult individuals. Panoramic X-rays were labeled on the basis of 32 classes in line with the FDI tooth numbering system. In order to examine the relationship between the number of data used in image processing algorithms and model performance, four different datasets which include 1000, 1500, 2000 and 2500 panoramic X-rays, were used. The training of the models was carried out with the YOLOv4 algorithm and trained models were tested on a fixed test dataset with 500 data and compared based on F1 score, mAP, sensitivity, precision and recall metrics.</p><p><strong>Results: </strong>The performance of the model increased as the number of data used during the training of the model increased. Therefore, the last model trained with 2500 data showed the highest success among all the trained models.</p><p><strong>Conclusion: </strong>Dataset size is important for dental enumeration, and large samples should be considered as more reliable.</p>","PeriodicalId":56103,"journal":{"name":"Oral Radiology","volume":"39 4","pages":"715-721"},"PeriodicalIF":1.7000,"publicationDate":"2023-10-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Oral Radiology","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1007/s11282-023-00689-4","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/7/5 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"DENTISTRY, ORAL SURGERY & MEDICINE","Score":null,"Total":0}
引用次数: 0
Abstract
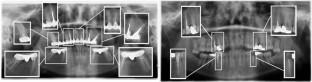
Objective: This study aims to investigate the effect of number of data on model performance, for the detection of tooth numbering problem on dental panoramic radiographs, with the help of image processing and deep learning algorithms.
Study design: The data set consists of 3000 anonymous dental panoramic X-rays of adult individuals. Panoramic X-rays were labeled on the basis of 32 classes in line with the FDI tooth numbering system. In order to examine the relationship between the number of data used in image processing algorithms and model performance, four different datasets which include 1000, 1500, 2000 and 2500 panoramic X-rays, were used. The training of the models was carried out with the YOLOv4 algorithm and trained models were tested on a fixed test dataset with 500 data and compared based on F1 score, mAP, sensitivity, precision and recall metrics.
Results: The performance of the model increased as the number of data used during the training of the model increased. Therefore, the last model trained with 2500 data showed the highest success among all the trained models.
Conclusion: Dataset size is important for dental enumeration, and large samples should be considered as more reliable.
期刊介绍:
As the official English-language journal of the Japanese Society for Oral and Maxillofacial Radiology and the Asian Academy of Oral and Maxillofacial Radiology, Oral Radiology is intended to be a forum for international collaboration in head and neck diagnostic imaging and all related fields. Oral Radiology features cutting-edge research papers, review articles, case reports, and technical notes from both the clinical and experimental fields. As membership in the Society is not a prerequisite, contributions are welcome from researchers and clinicians worldwide.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


