Laura Natalia Gonzalez-García, Daniela Lozano-Arce, Juan Pablo Londoño, Romain Guyot, Jorge Duitama
{"title":"Efficient homology-based annotation of transposable elements using minimizers","authors":"Laura Natalia Gonzalez-García, Daniela Lozano-Arce, Juan Pablo Londoño, Romain Guyot, Jorge Duitama","doi":"10.1002/aps3.11520","DOIUrl":null,"url":null,"abstract":"<div>\n \n \n <section>\n \n <h3> Premise</h3>\n \n <p>Transposable elements (TEs) make up more than half of the genomes of complex plant species and can modulate the expression of neighboring genes, producing significant variability of agronomically relevant traits. The availability of long-read sequencing technologies allows the building of genome assemblies for plant species with large and complex genomes. Unfortunately, TE annotation currently represents a bottleneck in the annotation of genome assemblies.</p>\n </section>\n \n <section>\n \n <h3> Methods and Results</h3>\n \n <p>We present a new functionality of the Next-Generation Sequencing Experience Platform (NGSEP) to perform efficient homology-based TE annotation. Sequences in a reference library are treated as long reads and mapped to an input genome assembly. A hierarchical annotation is then assigned by homology using the annotation of the reference library. We tested the performance of our algorithm on genome assemblies of different plant species, including <i>Arabidopsis thaliana</i>, <i>Oryza sativa, Coffea humblotiana</i>, and <i>Triticum aestivum</i> (bread wheat). Our algorithm outperforms traditional homology-based annotation tools in speed by a factor of three to >20, reducing the annotation time of the <i>T. aestivum</i> genome from months to hours, and recovering up to 80% of TEs annotated with RepeatMasker with a precision of up to 0.95.</p>\n </section>\n \n <section>\n \n <h3> Conclusions</h3>\n \n <p>NGSEP allows rapid analysis of TEs, especially in very large and TE-rich plant genomes.</p>\n </section>\n </div>","PeriodicalId":8022,"journal":{"name":"Applications in Plant Sciences","volume":"11 4","pages":""},"PeriodicalIF":2.7000,"publicationDate":"2023-05-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://bsapubs.onlinelibrary.wiley.com/doi/epdf/10.1002/aps3.11520","citationCount":"2","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Applications in Plant Sciences","FirstCategoryId":"99","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/aps3.11520","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"PLANT SCIENCES","Score":null,"Total":0}
引用次数: 2
Abstract
Premise
Transposable elements (TEs) make up more than half of the genomes of complex plant species and can modulate the expression of neighboring genes, producing significant variability of agronomically relevant traits. The availability of long-read sequencing technologies allows the building of genome assemblies for plant species with large and complex genomes. Unfortunately, TE annotation currently represents a bottleneck in the annotation of genome assemblies.
Methods and Results
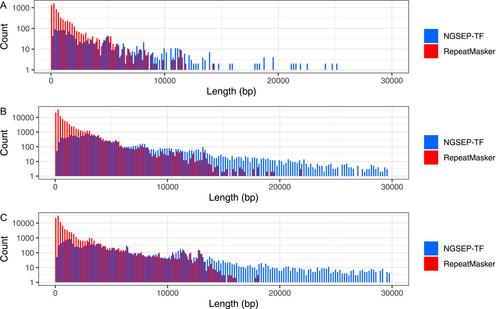
We present a new functionality of the Next-Generation Sequencing Experience Platform (NGSEP) to perform efficient homology-based TE annotation. Sequences in a reference library are treated as long reads and mapped to an input genome assembly. A hierarchical annotation is then assigned by homology using the annotation of the reference library. We tested the performance of our algorithm on genome assemblies of different plant species, including Arabidopsis thaliana, Oryza sativa, Coffea humblotiana, and Triticum aestivum (bread wheat). Our algorithm outperforms traditional homology-based annotation tools in speed by a factor of three to >20, reducing the annotation time of the T. aestivum genome from months to hours, and recovering up to 80% of TEs annotated with RepeatMasker with a precision of up to 0.95.
Conclusions
NGSEP allows rapid analysis of TEs, especially in very large and TE-rich plant genomes.
期刊介绍:
Applications in Plant Sciences (APPS) is a monthly, peer-reviewed, open access journal promoting the rapid dissemination of newly developed, innovative tools and protocols in all areas of the plant sciences, including genetics, structure, function, development, evolution, systematics, and ecology. Given the rapid progress today in technology and its application in the plant sciences, the goal of APPS is to foster communication within the plant science community to advance scientific research. APPS is a publication of the Botanical Society of America, originating in 2009 as the American Journal of Botany''s online-only section, AJB Primer Notes & Protocols in the Plant Sciences.
APPS publishes the following types of articles: (1) Protocol Notes describe new methods and technological advancements; (2) Genomic Resources Articles characterize the development and demonstrate the usefulness of newly developed genomic resources, including transcriptomes; (3) Software Notes detail new software applications; (4) Application Articles illustrate the application of a new protocol, method, or software application within the context of a larger study; (5) Review Articles evaluate available techniques, methods, or protocols; (6) Primer Notes report novel genetic markers with evidence of wide applicability.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


