Nat Mach Intell|多伦多大学:利用UniProt文本注释提升蛋白质表征预测能力的PAIR框架
智药邦
2025-09-22 08:00
文章摘要
背景:蛋白质功能预测是生物信息学和药物发现的核心挑战,现有蛋白质语言模型主要依赖序列保守性,但受进化与环境因素干扰,难以直接捕捉实验验证的功能信息。UniProt知识库积累了大量文本注释,却鲜有方法利用。研究目的:多伦多大学团队开发PAIR框架,通过序列到文本的注意力机制整合UniProt文本注释,提升蛋白质表示的预测能力和泛化性。结论:PAIR在训练任务上性能提升10%以上,在未见任务(如酶分类和基因本体预测)及低序列相似度场景下超越BLAST,尤其在少样本和低资源场景表现出色,为蛋白质功能预测提供了高效解决方案。

本站注明稿件来源为其他媒体的文/图等稿件均为转载稿,本站转载出于非商业性的教育和科研之目的,并不意味着赞同其观点或证实其内容的真实性。如转载稿涉及版权等问题,请作者速来电或来函联系。
智药邦

关于账号进行迁移的说明.
2025-10-20

专家点评Cell | 卢培龙团队及其合作者从头设计新型电压门控阴离子通道.
2025-10-20
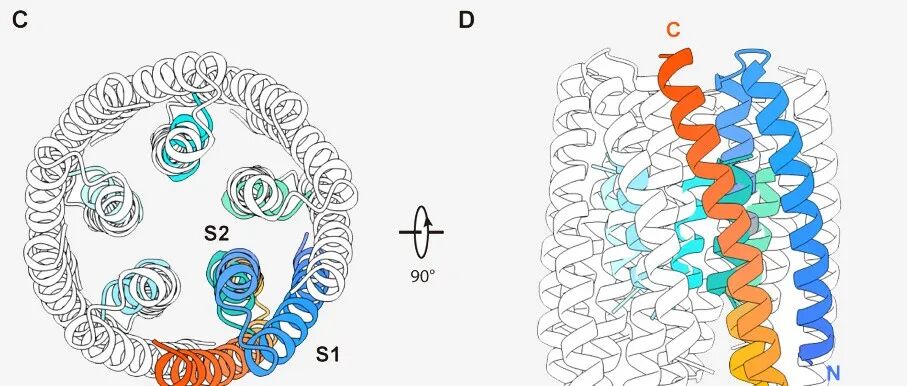
Cell|西湖大学卢培龙/黄晶等:从头设计新型电压门控阴离子通道.
2025-10-20

Sci Adv丨陈洛南课题组为计算生物学中的干预性因果推断提供新思路.
2025-10-20
Nature|麻省理工学院李巨团队:一种用于多组分电催化剂筛选的多模态机器人平台.
2025-10-19
最新文章
关于账号进行迁移的说明
2025-10-20
Sci Adv丨陈洛南课题组为计算生物学中的干预性因果推断提供新思路
2025-10-20
Cell|西湖大学卢培龙/黄晶等:从头设计新型电压门控阴离子通道
2025-10-20
专家点评Cell | 卢培龙团队及其合作者从头设计新型电压门控阴离子通道
2025-10-20

