万亿参数狂欢!一文刷爆2025年七大顶流大模型架构
计算材料学
2025-08-04 08:00
文章摘要
本文深入剖析了2025年顶级开源大模型的架构创新,重点关注DeepSeek V3、Kimi 2、Qwen3等模型的架构特点。背景方面,大模型架构从GPT-2到2025年看似相似,实则经历了诸多微创新。研究目的旨在揭示这些创新技术如何重塑模型效率与性能。结论表明,多头潜在注意力(MLA)、专家混合模型(MoE)和滑动窗口注意力等创新技术显著提升了模型的计算效率和性能。其中MLA通过键值张量压缩降低内存使用,MoE通过稀疏激活实现高参数利用率,滑动窗口注意力则通过局部注意力机制优化计算成本。这些架构创新使2025年的大模型在保持高性能的同时,大幅提升了计算效率。

本站注明稿件来源为其他媒体的文/图等稿件均为转载稿,本站转载出于非商业性的教育和科研之目的,并不意味着赞同其观点或证实其内容的真实性。如转载稿涉及版权等问题,请作者速来电或来函联系。
计算材料学
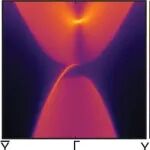

佛山大学物理与光电工程学院本科生在一年内连续发表4篇Physical Review B.
2025-12-30
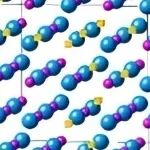
非化学计量钍基碳化物局部晶格畸变与热力学性质研究.
2025-12-30

佛山大学诚聘海内外高层次人才!.
2025-12-30

AI4S回归白盒符号主义,清华等联合发布SR-LLM:自主发现科学知识.
2025-12-30
最新文章





