Azade Tabaie, Srijan Sengupta, Zoe M Pruitt, Allan Fong
{"title":"一种自然语言处理方法,从患者安全事件报告中对贡献因素进行分类。","authors":"Azade Tabaie, Srijan Sengupta, Zoe M Pruitt, Allan Fong","doi":"10.1136/bmjhci-2022-100731","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>The objective of this study was to explore the use of natural language processing (NLP) algorithm to categorise contributing factors from patient safety event (PSE). Contributing factors are elements in the healthcare process (eg, communication failures) that instigate an event or allow an event to occur. Contributing factors can be used to further investigate why safety events occurred.</p><p><strong>Methods: </strong>We used 10 years of self-reported PSE reports from a multihospital healthcare system in the USA. Reports were first selected by event date. We calculated χ<sup>2</sup> values for each ngram in the bag-of-words then selected N ngrams with the highest χ<sup>2</sup> values. Then, PSE reports were filtered to only include the sentences containing the selected ngrams. Such sentences were called information-rich sentences. We compared two feature extraction techniques from free-text data: (1) baseline bag-of-words features and (2) features from information-rich sentences. Three machine learning algorithms were used to categorise five contributing factors representing sociotechnical errors: communication/hand-off failure, technology issue, policy/procedure issue, distractions/interruptions and lapse/slip. We trained 15 binary classifiers (five contributing factors * three machine learning models). The models' performances were evaluated according to the area under the precision-recall curve (AUPRC), precision, recall, and F1-score.</p><p><strong>Results: </strong>Applying the information-rich sentence selection algorithm boosted the contributing factor categorisation performance. Comparing the AUPRCs, the proposed NLP approach improved the categorisation performance of two and achieved comparable results with baseline in categorising three contributing factors.</p><p><strong>Conclusions: </strong>Information-rich sentence selection can be incorporated to extract the sentences in free-text event narratives in which the contributing factor information is embedded.</p>","PeriodicalId":9050,"journal":{"name":"BMJ Health & Care Informatics","volume":"30 1","pages":""},"PeriodicalIF":4.1000,"publicationDate":"2023-05-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/9e/ab/bmjhci-2022-100731.PMC10254979.pdf","citationCount":"0","resultStr":"{\"title\":\"A natural language processing approach to categorise contributing factors from patient safety event reports.\",\"authors\":\"Azade Tabaie, Srijan Sengupta, Zoe M Pruitt, Allan Fong\",\"doi\":\"10.1136/bmjhci-2022-100731\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objectives: </strong>The objective of this study was to explore the use of natural language processing (NLP) algorithm to categorise contributing factors from patient safety event (PSE). Contributing factors are elements in the healthcare process (eg, communication failures) that instigate an event or allow an event to occur. Contributing factors can be used to further investigate why safety events occurred.</p><p><strong>Methods: </strong>We used 10 years of self-reported PSE reports from a multihospital healthcare system in the USA. Reports were first selected by event date. We calculated χ<sup>2</sup> values for each ngram in the bag-of-words then selected N ngrams with the highest χ<sup>2</sup> values. Then, PSE reports were filtered to only include the sentences containing the selected ngrams. Such sentences were called information-rich sentences. We compared two feature extraction techniques from free-text data: (1) baseline bag-of-words features and (2) features from information-rich sentences. Three machine learning algorithms were used to categorise five contributing factors representing sociotechnical errors: communication/hand-off failure, technology issue, policy/procedure issue, distractions/interruptions and lapse/slip. We trained 15 binary classifiers (five contributing factors * three machine learning models). The models' performances were evaluated according to the area under the precision-recall curve (AUPRC), precision, recall, and F1-score.</p><p><strong>Results: </strong>Applying the information-rich sentence selection algorithm boosted the contributing factor categorisation performance. Comparing the AUPRCs, the proposed NLP approach improved the categorisation performance of two and achieved comparable results with baseline in categorising three contributing factors.</p><p><strong>Conclusions: </strong>Information-rich sentence selection can be incorporated to extract the sentences in free-text event narratives in which the contributing factor information is embedded.</p>\",\"PeriodicalId\":9050,\"journal\":{\"name\":\"BMJ Health & Care Informatics\",\"volume\":\"30 1\",\"pages\":\"\"},\"PeriodicalIF\":4.1000,\"publicationDate\":\"2023-05-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/9e/ab/bmjhci-2022-100731.PMC10254979.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"BMJ Health & Care Informatics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1136/bmjhci-2022-100731\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMJ Health & Care Informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1136/bmjhci-2022-100731","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
A natural language processing approach to categorise contributing factors from patient safety event reports.
Objectives: The objective of this study was to explore the use of natural language processing (NLP) algorithm to categorise contributing factors from patient safety event (PSE). Contributing factors are elements in the healthcare process (eg, communication failures) that instigate an event or allow an event to occur. Contributing factors can be used to further investigate why safety events occurred.
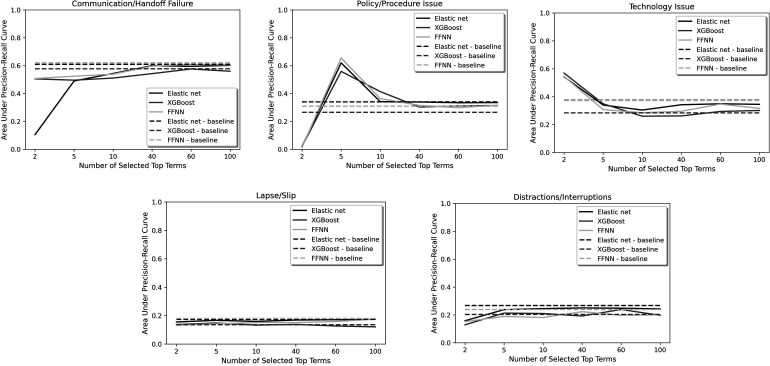
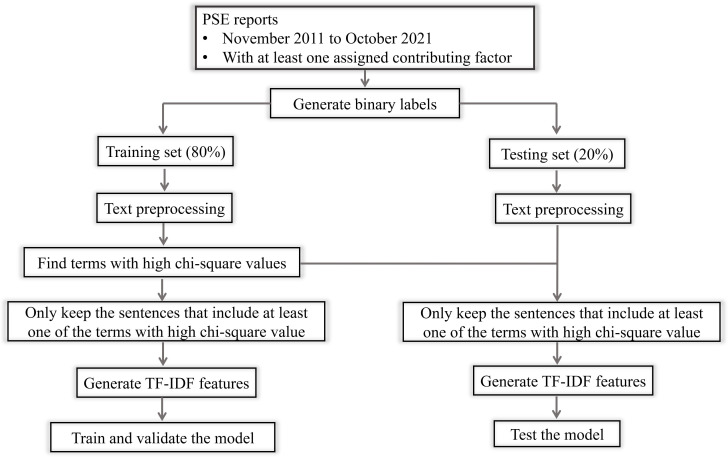
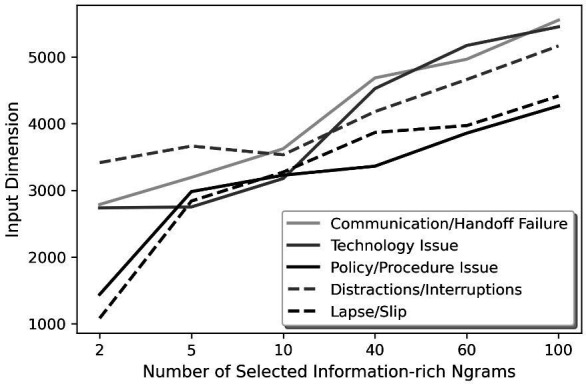
Methods: We used 10 years of self-reported PSE reports from a multihospital healthcare system in the USA. Reports were first selected by event date. We calculated χ2 values for each ngram in the bag-of-words then selected N ngrams with the highest χ2 values. Then, PSE reports were filtered to only include the sentences containing the selected ngrams. Such sentences were called information-rich sentences. We compared two feature extraction techniques from free-text data: (1) baseline bag-of-words features and (2) features from information-rich sentences. Three machine learning algorithms were used to categorise five contributing factors representing sociotechnical errors: communication/hand-off failure, technology issue, policy/procedure issue, distractions/interruptions and lapse/slip. We trained 15 binary classifiers (five contributing factors * three machine learning models). The models' performances were evaluated according to the area under the precision-recall curve (AUPRC), precision, recall, and F1-score.
Results: Applying the information-rich sentence selection algorithm boosted the contributing factor categorisation performance. Comparing the AUPRCs, the proposed NLP approach improved the categorisation performance of two and achieved comparable results with baseline in categorising three contributing factors.
Conclusions: Information-rich sentence selection can be incorporated to extract the sentences in free-text event narratives in which the contributing factor information is embedded.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


