Andrew J Vickers, Ben Van Claster, Laure Wynants, Ewout W Steyerberg
{"title":"决策曲线分析:置信区间和净效益假设检验。","authors":"Andrew J Vickers, Ben Van Claster, Laure Wynants, Ewout W Steyerberg","doi":"10.1186/s41512-023-00148-y","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>A number of recent papers have proposed methods to calculate confidence intervals and p values for net benefit used in decision curve analysis. These papers are sparse on the rationale for doing so. We aim to assess the relation between sampling variability, inference, and decision-analytic concepts.</p><p><strong>Methods and results: </strong>We review the underlying theory of decision analysis. When we are forced into a decision, we should choose the option with the highest expected utility, irrespective of p values or uncertainty. This is in some distinction to traditional hypothesis testing, where a decision such as whether to reject a given hypothesis can be postponed. Application of inference for net benefit would generally be harmful. In particular, insisting that differences in net benefit be statistically significant would dramatically change the criteria by which we consider a prediction model to be of value. We argue instead that uncertainty related to sampling variation for net benefit should be thought of in terms of the value of further research. Decision analysis tells us which decision to make for now, but we may also want to know how much confidence we should have in that decision. If we are insufficiently confident that we are right, further research is warranted.</p><p><strong>Conclusion: </strong>Null hypothesis testing or simple consideration of confidence intervals are of questionable value for decision curve analysis, and methods such as value of information analysis or approaches to assess the probability of benefit should be considered instead.</p>","PeriodicalId":72800,"journal":{"name":"Diagnostic and prognostic research","volume":"7 1","pages":"11"},"PeriodicalIF":2.6000,"publicationDate":"2023-06-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10243069/pdf/","citationCount":"0","resultStr":"{\"title\":\"Decision curve analysis: confidence intervals and hypothesis testing for net benefit.\",\"authors\":\"Andrew J Vickers, Ben Van Claster, Laure Wynants, Ewout W Steyerberg\",\"doi\":\"10.1186/s41512-023-00148-y\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>A number of recent papers have proposed methods to calculate confidence intervals and p values for net benefit used in decision curve analysis. These papers are sparse on the rationale for doing so. We aim to assess the relation between sampling variability, inference, and decision-analytic concepts.</p><p><strong>Methods and results: </strong>We review the underlying theory of decision analysis. When we are forced into a decision, we should choose the option with the highest expected utility, irrespective of p values or uncertainty. This is in some distinction to traditional hypothesis testing, where a decision such as whether to reject a given hypothesis can be postponed. Application of inference for net benefit would generally be harmful. In particular, insisting that differences in net benefit be statistically significant would dramatically change the criteria by which we consider a prediction model to be of value. We argue instead that uncertainty related to sampling variation for net benefit should be thought of in terms of the value of further research. Decision analysis tells us which decision to make for now, but we may also want to know how much confidence we should have in that decision. If we are insufficiently confident that we are right, further research is warranted.</p><p><strong>Conclusion: </strong>Null hypothesis testing or simple consideration of confidence intervals are of questionable value for decision curve analysis, and methods such as value of information analysis or approaches to assess the probability of benefit should be considered instead.</p>\",\"PeriodicalId\":72800,\"journal\":{\"name\":\"Diagnostic and prognostic research\",\"volume\":\"7 1\",\"pages\":\"11\"},\"PeriodicalIF\":2.6000,\"publicationDate\":\"2023-06-06\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10243069/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Diagnostic and prognostic research\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1186/s41512-023-00148-y\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Diagnostic and prognostic research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s41512-023-00148-y","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
摘要
背景:最近有多篇论文提出了计算决策曲线分析中净效益的置信区间和 p 值的方法。这些论文对这样做的理由论述不多。我们旨在评估抽样变异性、推论和决策分析概念之间的关系:我们回顾了决策分析的基本理论。当我们被迫做出决策时,无论 p 值或不确定性如何,我们都应选择预期效用最大的选项。这与传统的假设检验有所不同,在传统的假设检验中,是否拒绝某一假设等决策可以推迟。应用净效益推论通常是有害的。特别是,坚持净收益的差异必须在统计上具有显著性,这将极大地改变我们认为预测模型具有价值的标准。相反,我们认为,与净收益抽样变化有关的不确定性应从进一步研究的价值角度来考虑。决策分析告诉我们现在应该做什么决策,但我们可能还想知道我们对该决策应该有多大的信心。如果我们对自己的正确性没有足够的信心,就有必要开展进一步的研究:结论:零假设检验或简单地考虑置信区间对决策曲线分析的价值值得怀疑,应考虑信息价值分析或评估受益概率等方法。
Decision curve analysis: confidence intervals and hypothesis testing for net benefit.
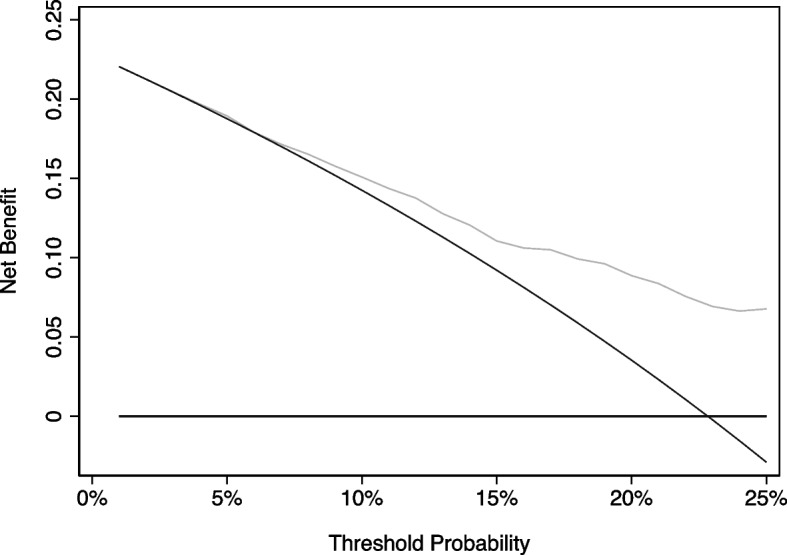
Background: A number of recent papers have proposed methods to calculate confidence intervals and p values for net benefit used in decision curve analysis. These papers are sparse on the rationale for doing so. We aim to assess the relation between sampling variability, inference, and decision-analytic concepts.
Methods and results: We review the underlying theory of decision analysis. When we are forced into a decision, we should choose the option with the highest expected utility, irrespective of p values or uncertainty. This is in some distinction to traditional hypothesis testing, where a decision such as whether to reject a given hypothesis can be postponed. Application of inference for net benefit would generally be harmful. In particular, insisting that differences in net benefit be statistically significant would dramatically change the criteria by which we consider a prediction model to be of value. We argue instead that uncertainty related to sampling variation for net benefit should be thought of in terms of the value of further research. Decision analysis tells us which decision to make for now, but we may also want to know how much confidence we should have in that decision. If we are insufficiently confident that we are right, further research is warranted.
Conclusion: Null hypothesis testing or simple consideration of confidence intervals are of questionable value for decision curve analysis, and methods such as value of information analysis or approaches to assess the probability of benefit should be considered instead.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


