Karine Pallier, Olivier Prot, Simone Naldi, Francisco Silva, Thierry Denis, Olivier Giry, Sophie Leobon, Elise Deluche, Nicole Tubiana-Mathieu
{"title":"病人识别和肿瘤识别管理:癌症多中心临床数据仓库的质量项目。","authors":"Karine Pallier, Olivier Prot, Simone Naldi, Francisco Silva, Thierry Denis, Olivier Giry, Sophie Leobon, Elise Deluche, Nicole Tubiana-Mathieu","doi":"10.1177/11769351231172609","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The Regional Basis of Solid Tumor (RBST), a clinical data warehouse, centralizes information related to cancer patient care in 5 health establishments in 2 French departments.</p><p><strong>Purpose: </strong>To develop algorithms matching heterogeneous data to \"real\" patients and \"real\" tumors with respect to patient identification (PI) and tumor identification (TI).</p><p><strong>Methods: </strong>A graph database programed in java Neo4j was used to build the RBST with data from ~20 000 patients. The PI algorithm using the Levenshtein distance was based on the regulatory criteria identifying a patient. A TI algorithm was built on 6 characteristics: tumor location and laterality, date of diagnosis, histology, primary and metastatic status. Given the heterogeneous nature and semantics of the collected data, the creation of repositories (organ, synonym, and histology repositories) was required. The TI algorithm used the Dice coefficient to match tumors.</p><p><strong>Results: </strong>Patients matched if there was complete agreement of the given name, surname, sex, and date/month/year of birth. These parameters were assigned weights of 28%, 28%, 21%, and 23% (with 18% for year, 2.5% for month, and 2.5% for day), respectively. The algorithm had a sensitivity of 99.69% (95% confidence interval [CI] [98.89%, 99.96%]) and a specificity of 100% (95% CI [99.72%, 100%]). The TI algorithm used repositories, weights were assigned to the diagnosis date and associated organ (37.5% and 37.5%, respectively), laterality (16%) histology (5%), and metastatic status (4%). This algorithm had a sensitivity of 71% (95% CI [62.68%, 78.25%]) and a specificity of 100% (95% CI [94.31%, 100%]).</p><p><strong>Conclusion: </strong>The RBST encompasses 2 quality controls: PI and TI. It facilitates the implementation of transversal structuring and assessments of the performance of the provided care.</p>","PeriodicalId":35418,"journal":{"name":"Cancer Informatics","volume":"22 ","pages":"11769351231172609"},"PeriodicalIF":2.5000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/f9/25/10.1177_11769351231172609.PMC10201142.pdf","citationCount":"0","resultStr":"{\"title\":\"Patient Identification and Tumor Identification Management: Quality Program in a Cancer Multicentric Clinical Data Warehouse.\",\"authors\":\"Karine Pallier, Olivier Prot, Simone Naldi, Francisco Silva, Thierry Denis, Olivier Giry, Sophie Leobon, Elise Deluche, Nicole Tubiana-Mathieu\",\"doi\":\"10.1177/11769351231172609\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>The Regional Basis of Solid Tumor (RBST), a clinical data warehouse, centralizes information related to cancer patient care in 5 health establishments in 2 French departments.</p><p><strong>Purpose: </strong>To develop algorithms matching heterogeneous data to \\\"real\\\" patients and \\\"real\\\" tumors with respect to patient identification (PI) and tumor identification (TI).</p><p><strong>Methods: </strong>A graph database programed in java Neo4j was used to build the RBST with data from ~20 000 patients. The PI algorithm using the Levenshtein distance was based on the regulatory criteria identifying a patient. A TI algorithm was built on 6 characteristics: tumor location and laterality, date of diagnosis, histology, primary and metastatic status. Given the heterogeneous nature and semantics of the collected data, the creation of repositories (organ, synonym, and histology repositories) was required. The TI algorithm used the Dice coefficient to match tumors.</p><p><strong>Results: </strong>Patients matched if there was complete agreement of the given name, surname, sex, and date/month/year of birth. These parameters were assigned weights of 28%, 28%, 21%, and 23% (with 18% for year, 2.5% for month, and 2.5% for day), respectively. The algorithm had a sensitivity of 99.69% (95% confidence interval [CI] [98.89%, 99.96%]) and a specificity of 100% (95% CI [99.72%, 100%]). The TI algorithm used repositories, weights were assigned to the diagnosis date and associated organ (37.5% and 37.5%, respectively), laterality (16%) histology (5%), and metastatic status (4%). This algorithm had a sensitivity of 71% (95% CI [62.68%, 78.25%]) and a specificity of 100% (95% CI [94.31%, 100%]).</p><p><strong>Conclusion: </strong>The RBST encompasses 2 quality controls: PI and TI. It facilitates the implementation of transversal structuring and assessments of the performance of the provided care.</p>\",\"PeriodicalId\":35418,\"journal\":{\"name\":\"Cancer Informatics\",\"volume\":\"22 \",\"pages\":\"11769351231172609\"},\"PeriodicalIF\":2.5000,\"publicationDate\":\"2023-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/f9/25/10.1177_11769351231172609.PMC10201142.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Cancer Informatics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1177/11769351231172609\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Cancer Informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1177/11769351231172609","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Patient Identification and Tumor Identification Management: Quality Program in a Cancer Multicentric Clinical Data Warehouse.
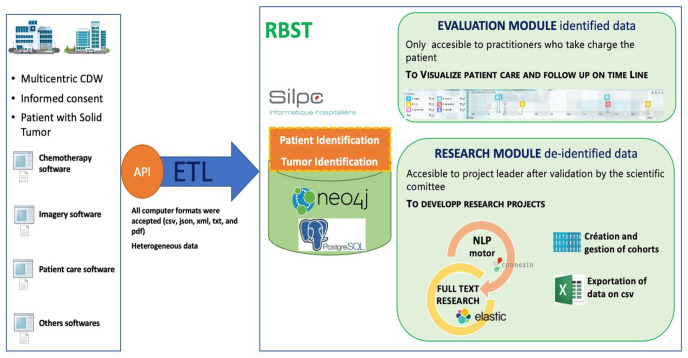
Background: The Regional Basis of Solid Tumor (RBST), a clinical data warehouse, centralizes information related to cancer patient care in 5 health establishments in 2 French departments.
Purpose: To develop algorithms matching heterogeneous data to "real" patients and "real" tumors with respect to patient identification (PI) and tumor identification (TI).
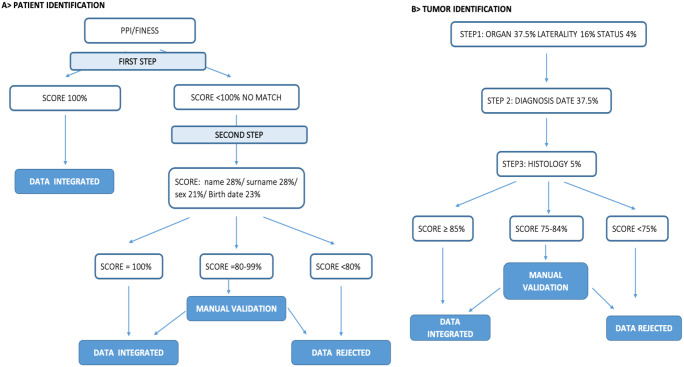
Methods: A graph database programed in java Neo4j was used to build the RBST with data from ~20 000 patients. The PI algorithm using the Levenshtein distance was based on the regulatory criteria identifying a patient. A TI algorithm was built on 6 characteristics: tumor location and laterality, date of diagnosis, histology, primary and metastatic status. Given the heterogeneous nature and semantics of the collected data, the creation of repositories (organ, synonym, and histology repositories) was required. The TI algorithm used the Dice coefficient to match tumors.
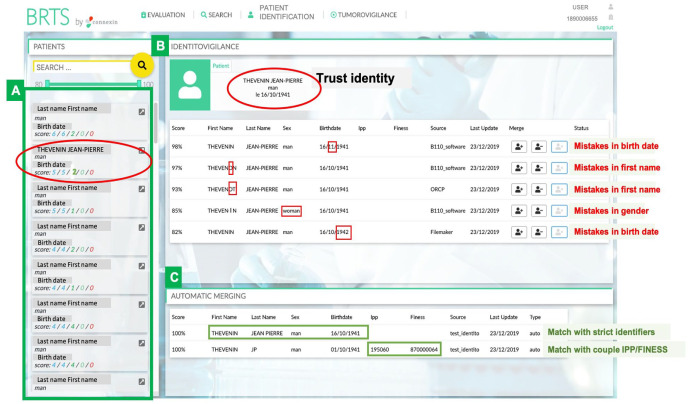
Results: Patients matched if there was complete agreement of the given name, surname, sex, and date/month/year of birth. These parameters were assigned weights of 28%, 28%, 21%, and 23% (with 18% for year, 2.5% for month, and 2.5% for day), respectively. The algorithm had a sensitivity of 99.69% (95% confidence interval [CI] [98.89%, 99.96%]) and a specificity of 100% (95% CI [99.72%, 100%]). The TI algorithm used repositories, weights were assigned to the diagnosis date and associated organ (37.5% and 37.5%, respectively), laterality (16%) histology (5%), and metastatic status (4%). This algorithm had a sensitivity of 71% (95% CI [62.68%, 78.25%]) and a specificity of 100% (95% CI [94.31%, 100%]).
Conclusion: The RBST encompasses 2 quality controls: PI and TI. It facilitates the implementation of transversal structuring and assessments of the performance of the provided care.
期刊介绍:
The field of cancer research relies on advances in many other disciplines, including omics technology, mass spectrometry, radio imaging, computer science, and biostatistics. Cancer Informatics provides open access to peer-reviewed high-quality manuscripts reporting bioinformatics analysis of molecular genetics and/or clinical data pertaining to cancer, emphasizing the use of machine learning, artificial intelligence, statistical algorithms, advanced imaging techniques, data visualization, and high-throughput technologies. As the leading journal dedicated exclusively to the report of the use of computational methods in cancer research and practice, Cancer Informatics leverages methodological improvements in systems biology, genomics, proteomics, metabolomics, and molecular biochemistry into the fields of cancer detection, treatment, classification, risk-prediction, prevention, outcome, and modeling.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


