Aaron Edward Casey, Saba Ansari, Bahareh Nakisa, Blair Kelly, Pieta Brown, Paul Cooper, Imran Muhammad, Steven Livingstone, Sandeep Reddy, Ville-Petteri Makinen
{"title":"综合评估框架在COVID-19研究中的应用:人工智能在医疗保健中的转化方面的系统综述","authors":"Aaron Edward Casey, Saba Ansari, Bahareh Nakisa, Blair Kelly, Pieta Brown, Paul Cooper, Imran Muhammad, Steven Livingstone, Sandeep Reddy, Ville-Petteri Makinen","doi":"10.2196/42313","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Despite immense progress in artificial intelligence (AI) models, there has been limited deployment in health care environments. The gap between potential and actual AI applications is likely due to the lack of translatability between controlled research environments (where these models are developed) and clinical environments for which the AI tools are ultimately intended.</p><p><strong>Objective: </strong>We previously developed the Translational Evaluation of Healthcare AI (TEHAI) framework to assess the translational value of AI models and to support successful transition to health care environments. In this study, we applied the TEHAI framework to the COVID-19 literature in order to assess how well translational topics are covered.</p><p><strong>Methods: </strong>A systematic literature search for COVID-19 AI studies published between December 2019 and December 2020 resulted in 3830 records. A subset of 102 (2.7%) papers that passed the inclusion criteria was sampled for full review. The papers were assessed for translational value and descriptive data collected by 9 reviewers (each study was assessed by 2 reviewers). Evaluation scores and extracted data were compared by a third reviewer for resolution of discrepancies. The review process was conducted on the Covidence software platform.</p><p><strong>Results: </strong>We observed a significant trend for studies to attain high scores for technical capability but low scores for the areas essential for clinical translatability. Specific questions regarding external model validation, safety, nonmaleficence, and service adoption received failed scores in most studies.</p><p><strong>Conclusions: </strong>Using TEHAI, we identified notable gaps in how well translational topics of AI models are covered in the COVID-19 clinical sphere. These gaps in areas crucial for clinical translatability could, and should, be considered already at the model development stage to increase translatability into real COVID-19 health care environments.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"2 ","pages":"e42313"},"PeriodicalIF":0.0000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10337329/pdf/","citationCount":"1","resultStr":"{\"title\":\"Application of a Comprehensive Evaluation Framework to COVID-19 Studies: Systematic Review of Translational Aspects of Artificial Intelligence in Health Care.\",\"authors\":\"Aaron Edward Casey, Saba Ansari, Bahareh Nakisa, Blair Kelly, Pieta Brown, Paul Cooper, Imran Muhammad, Steven Livingstone, Sandeep Reddy, Ville-Petteri Makinen\",\"doi\":\"10.2196/42313\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Despite immense progress in artificial intelligence (AI) models, there has been limited deployment in health care environments. The gap between potential and actual AI applications is likely due to the lack of translatability between controlled research environments (where these models are developed) and clinical environments for which the AI tools are ultimately intended.</p><p><strong>Objective: </strong>We previously developed the Translational Evaluation of Healthcare AI (TEHAI) framework to assess the translational value of AI models and to support successful transition to health care environments. In this study, we applied the TEHAI framework to the COVID-19 literature in order to assess how well translational topics are covered.</p><p><strong>Methods: </strong>A systematic literature search for COVID-19 AI studies published between December 2019 and December 2020 resulted in 3830 records. A subset of 102 (2.7%) papers that passed the inclusion criteria was sampled for full review. The papers were assessed for translational value and descriptive data collected by 9 reviewers (each study was assessed by 2 reviewers). Evaluation scores and extracted data were compared by a third reviewer for resolution of discrepancies. The review process was conducted on the Covidence software platform.</p><p><strong>Results: </strong>We observed a significant trend for studies to attain high scores for technical capability but low scores for the areas essential for clinical translatability. Specific questions regarding external model validation, safety, nonmaleficence, and service adoption received failed scores in most studies.</p><p><strong>Conclusions: </strong>Using TEHAI, we identified notable gaps in how well translational topics of AI models are covered in the COVID-19 clinical sphere. These gaps in areas crucial for clinical translatability could, and should, be considered already at the model development stage to increase translatability into real COVID-19 health care environments.</p>\",\"PeriodicalId\":73551,\"journal\":{\"name\":\"JMIR AI\",\"volume\":\"2 \",\"pages\":\"e42313\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2023-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10337329/pdf/\",\"citationCount\":\"1\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR AI\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/42313\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/42313","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Application of a Comprehensive Evaluation Framework to COVID-19 Studies: Systematic Review of Translational Aspects of Artificial Intelligence in Health Care.
Background: Despite immense progress in artificial intelligence (AI) models, there has been limited deployment in health care environments. The gap between potential and actual AI applications is likely due to the lack of translatability between controlled research environments (where these models are developed) and clinical environments for which the AI tools are ultimately intended.
Objective: We previously developed the Translational Evaluation of Healthcare AI (TEHAI) framework to assess the translational value of AI models and to support successful transition to health care environments. In this study, we applied the TEHAI framework to the COVID-19 literature in order to assess how well translational topics are covered.
Methods: A systematic literature search for COVID-19 AI studies published between December 2019 and December 2020 resulted in 3830 records. A subset of 102 (2.7%) papers that passed the inclusion criteria was sampled for full review. The papers were assessed for translational value and descriptive data collected by 9 reviewers (each study was assessed by 2 reviewers). Evaluation scores and extracted data were compared by a third reviewer for resolution of discrepancies. The review process was conducted on the Covidence software platform.
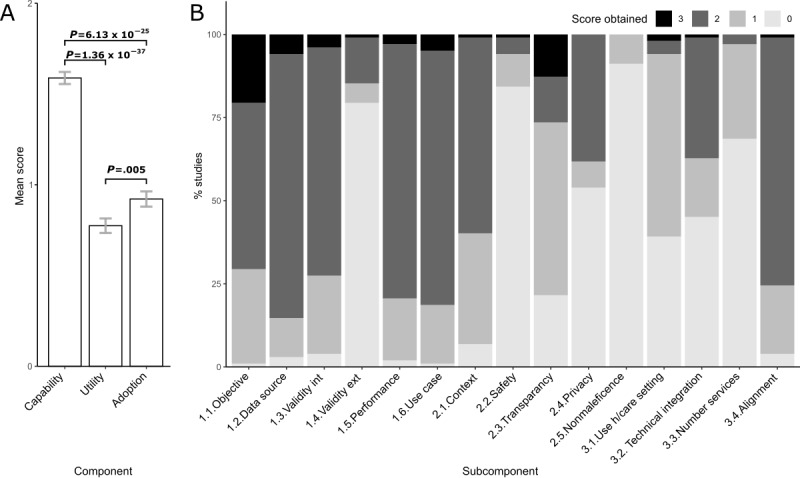
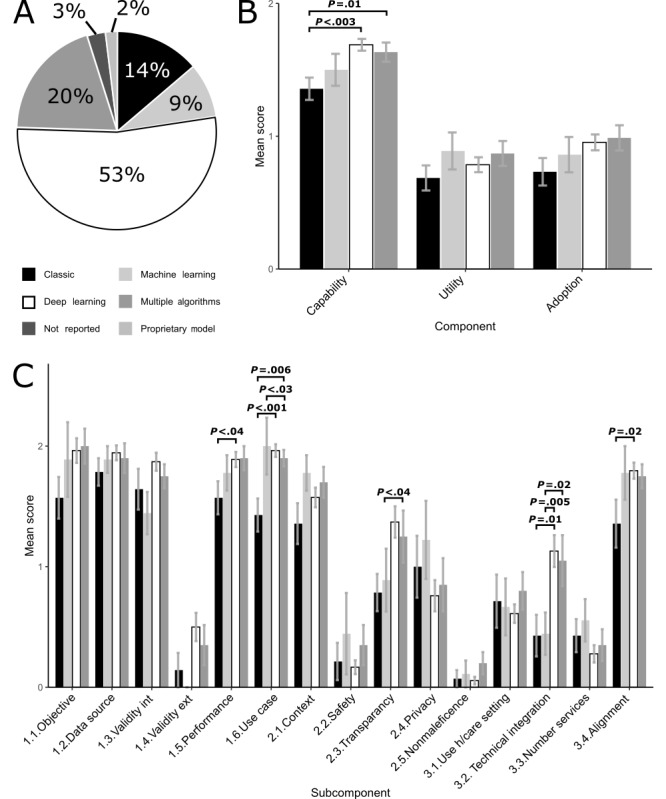
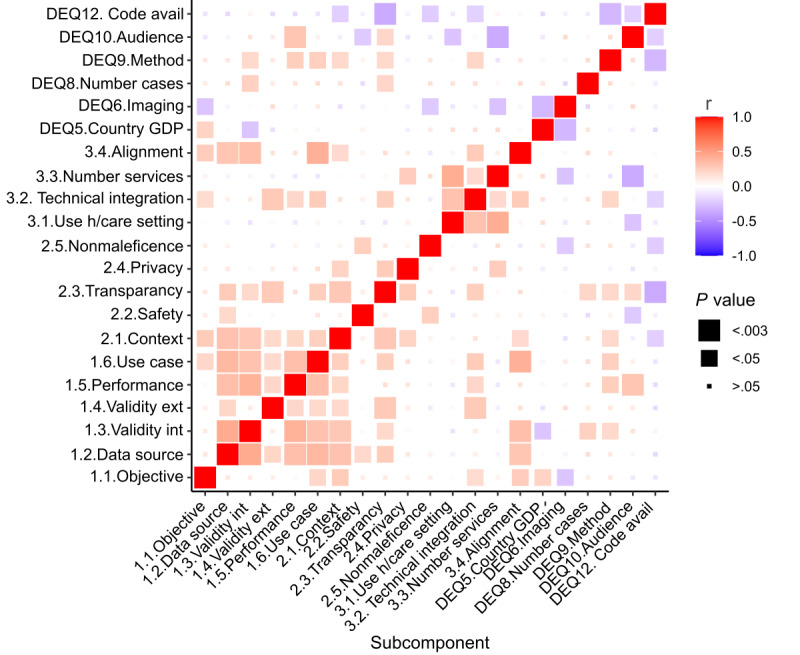
Results: We observed a significant trend for studies to attain high scores for technical capability but low scores for the areas essential for clinical translatability. Specific questions regarding external model validation, safety, nonmaleficence, and service adoption received failed scores in most studies.
Conclusions: Using TEHAI, we identified notable gaps in how well translational topics of AI models are covered in the COVID-19 clinical sphere. These gaps in areas crucial for clinical translatability could, and should, be considered already at the model development stage to increase translatability into real COVID-19 health care environments.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


