{"title":"数据共享约束下的异质性整合高维多重测试","authors":"Molei Liu, Yin Xia, Kelly Cho, Tianxi Cai","doi":"","DOIUrl":null,"url":null,"abstract":"<p><p>Identifying informative predictors in a high dimensional regression model is a critical step for association analysis and predictive modeling. Signal detection in the high dimensional setting often fails due to the limited sample size. One approach to improving power is through meta-analyzing multiple studies which address the same scientific question. However, integrative analysis of high dimensional data from multiple studies is challenging in the presence of between-study heterogeneity. The challenge is even more pronounced with additional data sharing constraints under which only summary data can be shared across different sites. In this paper, we propose a novel data shielding integrative large-scale testing (DSILT) approach to signal detection allowing between-study heterogeneity and not requiring the sharing of individual level data. Assuming the underlying high dimensional regression models of the data differ across studies yet share similar support, the proposed method incorporates proper integrative estimation and debiasing procedures to construct test statistics for the overall effects of specific covariates. We also develop a multiple testing procedure to identify significant effects while controlling the false discovery rate (FDR) and false discovery proportion (FDP). Theoretical comparisons of the new testing procedure with the ideal individual-level meta-analysis (ILMA) approach and other distributed inference methods are investigated. Simulation studies demonstrate that the proposed testing procedure performs well in both controlling false discovery and attaining power. The new method is applied to a real example detecting interaction effects of the genetic variants for statins and obesity on the risk for type II diabetes.</p>","PeriodicalId":50161,"journal":{"name":"Journal of Machine Learning Research","volume":"22 ","pages":""},"PeriodicalIF":5.2000,"publicationDate":"2021-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10327421/pdf/","citationCount":"0","resultStr":"{\"title\":\"Integrative High Dimensional Multiple Testing with Heterogeneity under Data Sharing Constraints.\",\"authors\":\"Molei Liu, Yin Xia, Kelly Cho, Tianxi Cai\",\"doi\":\"\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Identifying informative predictors in a high dimensional regression model is a critical step for association analysis and predictive modeling. Signal detection in the high dimensional setting often fails due to the limited sample size. One approach to improving power is through meta-analyzing multiple studies which address the same scientific question. However, integrative analysis of high dimensional data from multiple studies is challenging in the presence of between-study heterogeneity. The challenge is even more pronounced with additional data sharing constraints under which only summary data can be shared across different sites. In this paper, we propose a novel data shielding integrative large-scale testing (DSILT) approach to signal detection allowing between-study heterogeneity and not requiring the sharing of individual level data. Assuming the underlying high dimensional regression models of the data differ across studies yet share similar support, the proposed method incorporates proper integrative estimation and debiasing procedures to construct test statistics for the overall effects of specific covariates. We also develop a multiple testing procedure to identify significant effects while controlling the false discovery rate (FDR) and false discovery proportion (FDP). Theoretical comparisons of the new testing procedure with the ideal individual-level meta-analysis (ILMA) approach and other distributed inference methods are investigated. Simulation studies demonstrate that the proposed testing procedure performs well in both controlling false discovery and attaining power. The new method is applied to a real example detecting interaction effects of the genetic variants for statins and obesity on the risk for type II diabetes.</p>\",\"PeriodicalId\":50161,\"journal\":{\"name\":\"Journal of Machine Learning Research\",\"volume\":\"22 \",\"pages\":\"\"},\"PeriodicalIF\":5.2000,\"publicationDate\":\"2021-04-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10327421/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Machine Learning Research\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"AUTOMATION & CONTROL SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Machine Learning Research","FirstCategoryId":"94","ListUrlMain":"","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"AUTOMATION & CONTROL SYSTEMS","Score":null,"Total":0}
引用次数: 0
摘要
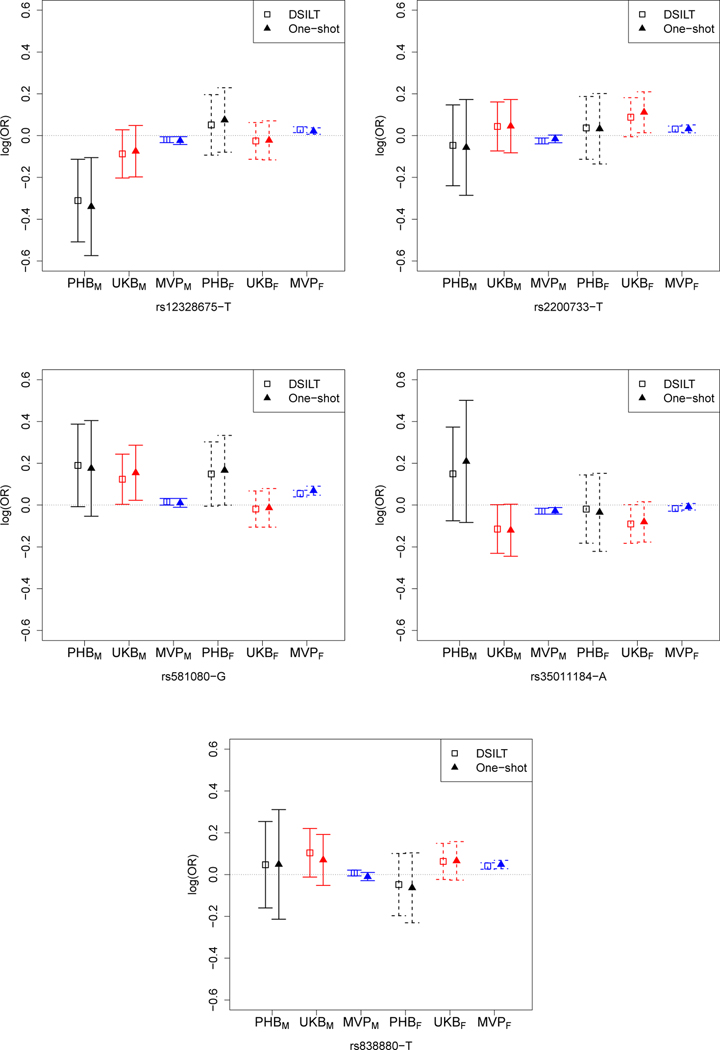
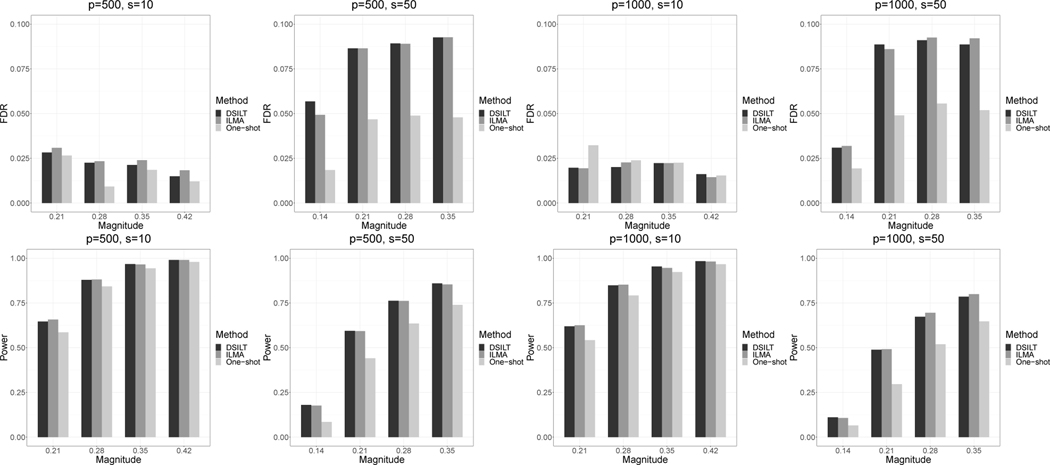
在高维回归模型中识别有信息量的预测因子是关联分析和预测建模的关键步骤。由于样本量有限,高维环境下的信号检测往往会失败。提高分析能力的一种方法是对涉及同一科学问题的多项研究进行荟萃分析。然而,在存在研究间异质性的情况下,对来自多项研究的高维数据进行综合分析具有挑战性。在额外的数据共享限制条件下,不同研究地点之间只能共享摘要数据,因此这一挑战就更加突出。在本文中,我们提出了一种新颖的数据屏蔽集成大规模测试(DSILT)方法来进行信号检测,这种方法允许研究间异质性,而且不需要共享个体水平的数据。假设不同研究的基础高维数据回归模型各不相同,但具有相似的支持,所提出的方法结合了适当的整合估计和去杂程序,以构建特定协变量总体效应的检验统计量。我们还开发了多重检验程序,在控制误发现率(FDR)和误发现比例(FDP)的同时识别显著效应。我们研究了新测试程序与理想个体水平荟萃分析(ILMA)方法和其他分布式推断方法的理论比较。模拟研究表明,建议的测试程序在控制误发现率和获得功率方面都表现出色。新方法被应用于一个实际例子,检测他汀类药物和肥胖的遗传变异对 II 型糖尿病风险的交互效应。
Integrative High Dimensional Multiple Testing with Heterogeneity under Data Sharing Constraints.
Identifying informative predictors in a high dimensional regression model is a critical step for association analysis and predictive modeling. Signal detection in the high dimensional setting often fails due to the limited sample size. One approach to improving power is through meta-analyzing multiple studies which address the same scientific question. However, integrative analysis of high dimensional data from multiple studies is challenging in the presence of between-study heterogeneity. The challenge is even more pronounced with additional data sharing constraints under which only summary data can be shared across different sites. In this paper, we propose a novel data shielding integrative large-scale testing (DSILT) approach to signal detection allowing between-study heterogeneity and not requiring the sharing of individual level data. Assuming the underlying high dimensional regression models of the data differ across studies yet share similar support, the proposed method incorporates proper integrative estimation and debiasing procedures to construct test statistics for the overall effects of specific covariates. We also develop a multiple testing procedure to identify significant effects while controlling the false discovery rate (FDR) and false discovery proportion (FDP). Theoretical comparisons of the new testing procedure with the ideal individual-level meta-analysis (ILMA) approach and other distributed inference methods are investigated. Simulation studies demonstrate that the proposed testing procedure performs well in both controlling false discovery and attaining power. The new method is applied to a real example detecting interaction effects of the genetic variants for statins and obesity on the risk for type II diabetes.
期刊介绍:
The Journal of Machine Learning Research (JMLR) provides an international forum for the electronic and paper publication of high-quality scholarly articles in all areas of machine learning. All published papers are freely available online.
JMLR has a commitment to rigorous yet rapid reviewing.
JMLR seeks previously unpublished papers on machine learning that contain:
new principled algorithms with sound empirical validation, and with justification of theoretical, psychological, or biological nature;
experimental and/or theoretical studies yielding new insight into the design and behavior of learning in intelligent systems;
accounts of applications of existing techniques that shed light on the strengths and weaknesses of the methods;
formalization of new learning tasks (e.g., in the context of new applications) and of methods for assessing performance on those tasks;
development of new analytical frameworks that advance theoretical studies of practical learning methods;
computational models of data from natural learning systems at the behavioral or neural level; or extremely well-written surveys of existing work.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


