Juan M Banda, Nigam H Shah, Vyjeyanthi S Periyakoil
{"title":"表征老年人中概率表型算法的亚组表现:痴呆、轻度认知障碍、阿尔茨海默病和帕金森病的案例研究","authors":"Juan M Banda, Nigam H Shah, Vyjeyanthi S Periyakoil","doi":"10.1093/jamiaopen/ooad043","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>Biases within probabilistic electronic phenotyping algorithms are largely unexplored. In this work, we characterize differences in subgroup performance of phenotyping algorithms for Alzheimer's disease and related dementias (ADRD) in older adults.</p><p><strong>Materials and methods: </strong>We created an experimental framework to characterize the performance of probabilistic phenotyping algorithms under different racial distributions allowing us to identify which algorithms may have differential performance, by how much, and under what conditions. We relied on rule-based phenotype definitions as reference to evaluate probabilistic phenotype algorithms created using the Automated PHenotype Routine for Observational Definition, Identification, Training and Evaluation framework.</p><p><strong>Results: </strong>We demonstrate that some algorithms have performance variations anywhere from 3% to 30% for different populations, even when not using race as an input variable. We show that while performance differences in subgroups are not present for all phenotypes, they do affect some phenotypes and groups more disproportionately than others.</p><p><strong>Discussion: </strong>Our analysis establishes the need for a robust evaluation framework for subgroup differences. The underlying patient populations for the algorithms showing subgroup performance differences have great variance between model features when compared with the phenotypes with little to no differences.</p><p><strong>Conclusion: </strong>We have created a framework to identify systematic differences in the performance of probabilistic phenotyping algorithms specifically in the context of ADRD as a use case. Differences in subgroup performance of probabilistic phenotyping algorithms are not widespread nor do they occur consistently. This highlights the great need for careful ongoing monitoring to evaluate, measure, and try to mitigate such differences.</p>","PeriodicalId":36278,"journal":{"name":"JAMIA Open","volume":"6 2","pages":"ooad043"},"PeriodicalIF":2.5000,"publicationDate":"2023-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/63/87/ooad043.PMC10307941.pdf","citationCount":"0","resultStr":"{\"title\":\"Characterizing subgroup performance of probabilistic phenotype algorithms within older adults: a case study for dementia, mild cognitive impairment, and Alzheimer's and Parkinson's diseases.\",\"authors\":\"Juan M Banda, Nigam H Shah, Vyjeyanthi S Periyakoil\",\"doi\":\"10.1093/jamiaopen/ooad043\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objective: </strong>Biases within probabilistic electronic phenotyping algorithms are largely unexplored. In this work, we characterize differences in subgroup performance of phenotyping algorithms for Alzheimer's disease and related dementias (ADRD) in older adults.</p><p><strong>Materials and methods: </strong>We created an experimental framework to characterize the performance of probabilistic phenotyping algorithms under different racial distributions allowing us to identify which algorithms may have differential performance, by how much, and under what conditions. We relied on rule-based phenotype definitions as reference to evaluate probabilistic phenotype algorithms created using the Automated PHenotype Routine for Observational Definition, Identification, Training and Evaluation framework.</p><p><strong>Results: </strong>We demonstrate that some algorithms have performance variations anywhere from 3% to 30% for different populations, even when not using race as an input variable. We show that while performance differences in subgroups are not present for all phenotypes, they do affect some phenotypes and groups more disproportionately than others.</p><p><strong>Discussion: </strong>Our analysis establishes the need for a robust evaluation framework for subgroup differences. The underlying patient populations for the algorithms showing subgroup performance differences have great variance between model features when compared with the phenotypes with little to no differences.</p><p><strong>Conclusion: </strong>We have created a framework to identify systematic differences in the performance of probabilistic phenotyping algorithms specifically in the context of ADRD as a use case. Differences in subgroup performance of probabilistic phenotyping algorithms are not widespread nor do they occur consistently. This highlights the great need for careful ongoing monitoring to evaluate, measure, and try to mitigate such differences.</p>\",\"PeriodicalId\":36278,\"journal\":{\"name\":\"JAMIA Open\",\"volume\":\"6 2\",\"pages\":\"ooad043\"},\"PeriodicalIF\":2.5000,\"publicationDate\":\"2023-07-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/63/87/ooad043.PMC10307941.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JAMIA Open\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/jamiaopen/ooad043\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAMIA Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/jamiaopen/ooad043","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Characterizing subgroup performance of probabilistic phenotype algorithms within older adults: a case study for dementia, mild cognitive impairment, and Alzheimer's and Parkinson's diseases.
Objective: Biases within probabilistic electronic phenotyping algorithms are largely unexplored. In this work, we characterize differences in subgroup performance of phenotyping algorithms for Alzheimer's disease and related dementias (ADRD) in older adults.
Materials and methods: We created an experimental framework to characterize the performance of probabilistic phenotyping algorithms under different racial distributions allowing us to identify which algorithms may have differential performance, by how much, and under what conditions. We relied on rule-based phenotype definitions as reference to evaluate probabilistic phenotype algorithms created using the Automated PHenotype Routine for Observational Definition, Identification, Training and Evaluation framework.
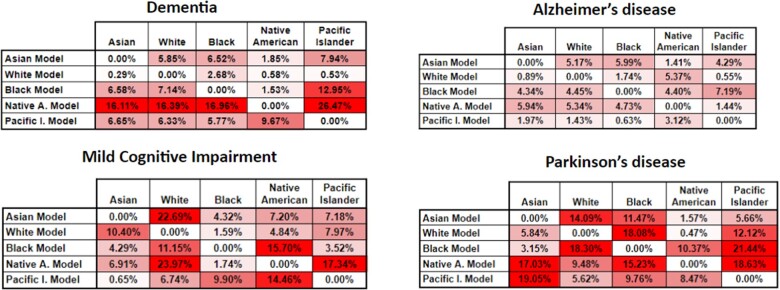
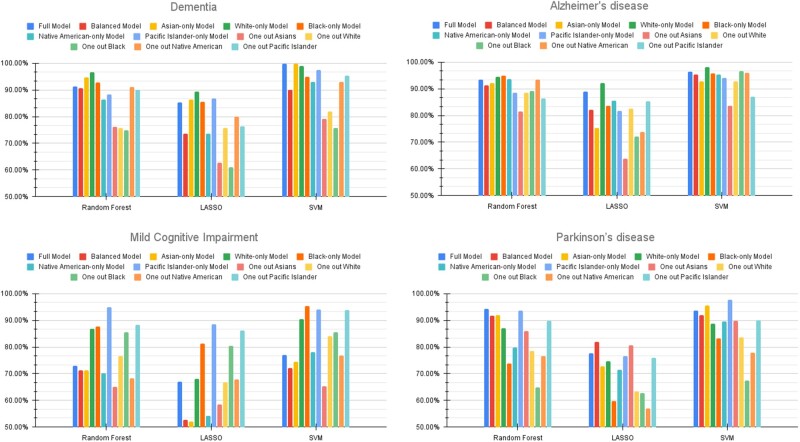
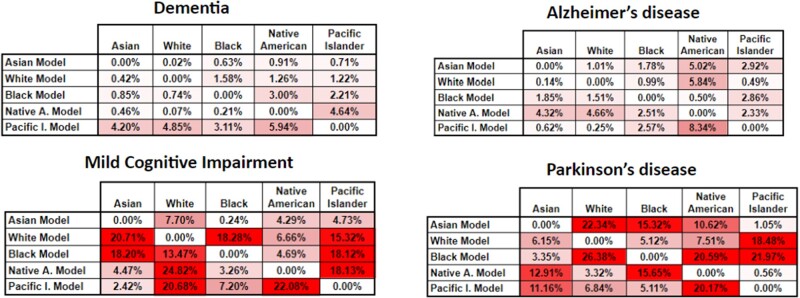
Results: We demonstrate that some algorithms have performance variations anywhere from 3% to 30% for different populations, even when not using race as an input variable. We show that while performance differences in subgroups are not present for all phenotypes, they do affect some phenotypes and groups more disproportionately than others.
Discussion: Our analysis establishes the need for a robust evaluation framework for subgroup differences. The underlying patient populations for the algorithms showing subgroup performance differences have great variance between model features when compared with the phenotypes with little to no differences.
Conclusion: We have created a framework to identify systematic differences in the performance of probabilistic phenotyping algorithms specifically in the context of ADRD as a use case. Differences in subgroup performance of probabilistic phenotyping algorithms are not widespread nor do they occur consistently. This highlights the great need for careful ongoing monitoring to evaluate, measure, and try to mitigate such differences.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


