Mónica Mora, Pablo González, José Ramón Quevedo, Elena Montañés, Llibertat Tusell, Rob Bergsma, Miriam Piles
{"title":"多输出和堆叠方法对使用机器学习算法从基因型预测饲料效率的影响。","authors":"Mónica Mora, Pablo González, José Ramón Quevedo, Elena Montañés, Llibertat Tusell, Rob Bergsma, Miriam Piles","doi":"10.1111/jbg.12815","DOIUrl":null,"url":null,"abstract":"<p>Feeding represents the largest economic cost in meat production; therefore, selection to improve traits related to feed efficiency is a goal in most livestock breeding programs. Residual feed intake (RFI), that is, the difference between the actual and the expected feed intake based on animal's requirements, has been used as the selection criteria to improve feed efficiency since it was proposed by Kotch in 1963. In growing pigs, it is computed as the residual of the multiple regression model of daily feed intake (DFI), on average daily gain (ADG), backfat thickness (BFT), and metabolic body weight (MW). Recently, prediction using single-output machine learning algorithms and information from SNPs as predictor variables have been proposed for genomic selection in growing pigs, but like in other species, the prediction quality achieved for RFI has been generally poor. However, it has been suggested that it could be improved through multi-output or stacking methods. For this purpose, four strategies were implemented to predict RFI. Two of them correspond to the computation of RFI in an indirect way using the predicted values of its components obtained from (i) individual (multiple single-output strategy) or (ii) simultaneous predictions (multi-output strategy). The other two correspond to the direct prediction of RFI using (iii) the individual predictions of its components as predictor variables jointly with the genotype (stacking strategy), or (iv) using only the genotypes as predictors of RFI (single-output strategy). The single-output strategy was considered the benchmark. This research aimed to test the former three hypotheses using data recorded from 5828 growing pigs and 45,610 SNPs. For all the strategies two different learning methods were fitted: random forest (RF) and support vector regression (SVR). A nested cross-validation (CV) with an outer 10-folds CV and an inner threefold CV for hyperparameter tuning was implemented to test all strategies. This scheme was repeated using as predictor variables different subsets with an increasing number (from 200 to 3000) of the most informative SNPs identified with RF. Results showed that the highest prediction performance was achieved with 1000 SNPs, although the stability of feature selection was poor (0.13 points out of 1). For all SNP subsets, the benchmark showed the best prediction performance. Using the RF as a learner and the 1000 most informative SNPs as predictors, the mean (SD) of the 10 values obtained in the test sets were: 0.23 (0.04) for the Spearman correlation, 0.83 (0.04) for the zero–one loss, and 0.33 (0.03) for the rank distance loss. We conclude that the information on predicted components of RFI (DFI, ADG, MW, and BFT) does not contribute to improve the quality of the prediction of this trait in relation to the one obtained with the single-output strategy.</p>","PeriodicalId":54885,"journal":{"name":"Journal of Animal Breeding and Genetics","volume":"140 6","pages":"638-652"},"PeriodicalIF":1.9000,"publicationDate":"2023-07-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/jbg.12815","citationCount":"0","resultStr":"{\"title\":\"Impact of multi-output and stacking methods on feed efficiency prediction from genotype using machine learning algorithms\",\"authors\":\"Mónica Mora, Pablo González, José Ramón Quevedo, Elena Montañés, Llibertat Tusell, Rob Bergsma, Miriam Piles\",\"doi\":\"10.1111/jbg.12815\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Feeding represents the largest economic cost in meat production; therefore, selection to improve traits related to feed efficiency is a goal in most livestock breeding programs. Residual feed intake (RFI), that is, the difference between the actual and the expected feed intake based on animal's requirements, has been used as the selection criteria to improve feed efficiency since it was proposed by Kotch in 1963. In growing pigs, it is computed as the residual of the multiple regression model of daily feed intake (DFI), on average daily gain (ADG), backfat thickness (BFT), and metabolic body weight (MW). Recently, prediction using single-output machine learning algorithms and information from SNPs as predictor variables have been proposed for genomic selection in growing pigs, but like in other species, the prediction quality achieved for RFI has been generally poor. However, it has been suggested that it could be improved through multi-output or stacking methods. For this purpose, four strategies were implemented to predict RFI. Two of them correspond to the computation of RFI in an indirect way using the predicted values of its components obtained from (i) individual (multiple single-output strategy) or (ii) simultaneous predictions (multi-output strategy). The other two correspond to the direct prediction of RFI using (iii) the individual predictions of its components as predictor variables jointly with the genotype (stacking strategy), or (iv) using only the genotypes as predictors of RFI (single-output strategy). The single-output strategy was considered the benchmark. This research aimed to test the former three hypotheses using data recorded from 5828 growing pigs and 45,610 SNPs. For all the strategies two different learning methods were fitted: random forest (RF) and support vector regression (SVR). A nested cross-validation (CV) with an outer 10-folds CV and an inner threefold CV for hyperparameter tuning was implemented to test all strategies. This scheme was repeated using as predictor variables different subsets with an increasing number (from 200 to 3000) of the most informative SNPs identified with RF. Results showed that the highest prediction performance was achieved with 1000 SNPs, although the stability of feature selection was poor (0.13 points out of 1). For all SNP subsets, the benchmark showed the best prediction performance. Using the RF as a learner and the 1000 most informative SNPs as predictors, the mean (SD) of the 10 values obtained in the test sets were: 0.23 (0.04) for the Spearman correlation, 0.83 (0.04) for the zero–one loss, and 0.33 (0.03) for the rank distance loss. We conclude that the information on predicted components of RFI (DFI, ADG, MW, and BFT) does not contribute to improve the quality of the prediction of this trait in relation to the one obtained with the single-output strategy.</p>\",\"PeriodicalId\":54885,\"journal\":{\"name\":\"Journal of Animal Breeding and Genetics\",\"volume\":\"140 6\",\"pages\":\"638-652\"},\"PeriodicalIF\":1.9000,\"publicationDate\":\"2023-07-05\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1111/jbg.12815\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Animal Breeding and Genetics\",\"FirstCategoryId\":\"97\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1111/jbg.12815\",\"RegionNum\":3,\"RegionCategory\":\"农林科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"AGRICULTURE, DAIRY & ANIMAL SCIENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Animal Breeding and Genetics","FirstCategoryId":"97","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/jbg.12815","RegionNum":3,"RegionCategory":"农林科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"AGRICULTURE, DAIRY & ANIMAL SCIENCE","Score":null,"Total":0}
Impact of multi-output and stacking methods on feed efficiency prediction from genotype using machine learning algorithms
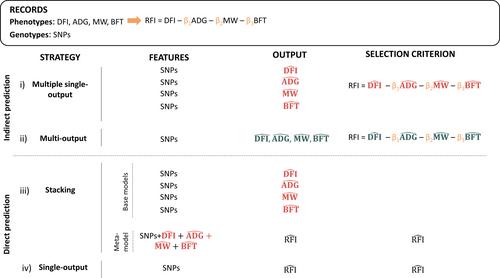
Feeding represents the largest economic cost in meat production; therefore, selection to improve traits related to feed efficiency is a goal in most livestock breeding programs. Residual feed intake (RFI), that is, the difference between the actual and the expected feed intake based on animal's requirements, has been used as the selection criteria to improve feed efficiency since it was proposed by Kotch in 1963. In growing pigs, it is computed as the residual of the multiple regression model of daily feed intake (DFI), on average daily gain (ADG), backfat thickness (BFT), and metabolic body weight (MW). Recently, prediction using single-output machine learning algorithms and information from SNPs as predictor variables have been proposed for genomic selection in growing pigs, but like in other species, the prediction quality achieved for RFI has been generally poor. However, it has been suggested that it could be improved through multi-output or stacking methods. For this purpose, four strategies were implemented to predict RFI. Two of them correspond to the computation of RFI in an indirect way using the predicted values of its components obtained from (i) individual (multiple single-output strategy) or (ii) simultaneous predictions (multi-output strategy). The other two correspond to the direct prediction of RFI using (iii) the individual predictions of its components as predictor variables jointly with the genotype (stacking strategy), or (iv) using only the genotypes as predictors of RFI (single-output strategy). The single-output strategy was considered the benchmark. This research aimed to test the former three hypotheses using data recorded from 5828 growing pigs and 45,610 SNPs. For all the strategies two different learning methods were fitted: random forest (RF) and support vector regression (SVR). A nested cross-validation (CV) with an outer 10-folds CV and an inner threefold CV for hyperparameter tuning was implemented to test all strategies. This scheme was repeated using as predictor variables different subsets with an increasing number (from 200 to 3000) of the most informative SNPs identified with RF. Results showed that the highest prediction performance was achieved with 1000 SNPs, although the stability of feature selection was poor (0.13 points out of 1). For all SNP subsets, the benchmark showed the best prediction performance. Using the RF as a learner and the 1000 most informative SNPs as predictors, the mean (SD) of the 10 values obtained in the test sets were: 0.23 (0.04) for the Spearman correlation, 0.83 (0.04) for the zero–one loss, and 0.33 (0.03) for the rank distance loss. We conclude that the information on predicted components of RFI (DFI, ADG, MW, and BFT) does not contribute to improve the quality of the prediction of this trait in relation to the one obtained with the single-output strategy.
期刊介绍:
The Journal of Animal Breeding and Genetics publishes original articles by international scientists on genomic selection, and any other topic related to breeding programmes, selection, quantitative genetic, genomics, diversity and evolution of domestic animals. Researchers, teachers, and the animal breeding industry will find the reports of interest. Book reviews appear in many issues.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


