{"title":"大型社交媒体企业分析策略:抽样和关键词提取方法。","authors":"Antonio Moreno-Ortiz, María García-Gámez","doi":"10.1007/s41701-023-00143-0","DOIUrl":null,"url":null,"abstract":"<p><p>In the context of the COVID-19 pandemic, social media platforms such as Twitter have been of great importance for users to exchange news, ideas, and perceptions. Researchers from fields such as discourse analysis and the social sciences have resorted to this content to explore public opinion and stance on this topic, and they have tried to gather information through the compilation of large-scale corpora. However, the size of such corpora is both an advantage and a drawback, as simple text retrieval techniques and tools may prove to be impractical or altogether incapable of handling such masses of data. This study provides methodological and practical cues on how to manage the contents of a large-scale social media corpus such as Chen et al. (JMIR Public Health Surveill 6(2):e19273, 2020) COVID-19 corpus. We compare and evaluate, in terms of efficiency and efficacy, available methods to handle such a large corpus. First, we compare different sample sizes to assess whether it is possible to achieve similar results despite the size difference and evaluate sampling methods following a specific data management approach to storing the original corpus. Second, we examine two keyword extraction methodologies commonly used to obtain a compact representation of the main subject and topics of a text: the traditional method used in corpus linguistics, which compares word frequencies using a reference corpus, and graph-based techniques as developed in Natural Language Processing tasks. The methods and strategies discussed in this study enable valuable quantitative and qualitative analyses of an otherwise intractable mass of social media data.</p>","PeriodicalId":72709,"journal":{"name":"","volume":" ","pages":"1-25"},"PeriodicalIF":0.0,"publicationDate":"2023-04-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10148754/pdf/","citationCount":"2","resultStr":"{\"title\":\"Strategies for the Analysis of Large Social Media Corpora: Sampling and Keyword Extraction Methods.\",\"authors\":\"Antonio Moreno-Ortiz, María García-Gámez\",\"doi\":\"10.1007/s41701-023-00143-0\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>In the context of the COVID-19 pandemic, social media platforms such as Twitter have been of great importance for users to exchange news, ideas, and perceptions. Researchers from fields such as discourse analysis and the social sciences have resorted to this content to explore public opinion and stance on this topic, and they have tried to gather information through the compilation of large-scale corpora. However, the size of such corpora is both an advantage and a drawback, as simple text retrieval techniques and tools may prove to be impractical or altogether incapable of handling such masses of data. This study provides methodological and practical cues on how to manage the contents of a large-scale social media corpus such as Chen et al. (JMIR Public Health Surveill 6(2):e19273, 2020) COVID-19 corpus. We compare and evaluate, in terms of efficiency and efficacy, available methods to handle such a large corpus. First, we compare different sample sizes to assess whether it is possible to achieve similar results despite the size difference and evaluate sampling methods following a specific data management approach to storing the original corpus. Second, we examine two keyword extraction methodologies commonly used to obtain a compact representation of the main subject and topics of a text: the traditional method used in corpus linguistics, which compares word frequencies using a reference corpus, and graph-based techniques as developed in Natural Language Processing tasks. The methods and strategies discussed in this study enable valuable quantitative and qualitative analyses of an otherwise intractable mass of social media data.</p>\",\"PeriodicalId\":72709,\"journal\":{\"name\":\"\",\"volume\":\" \",\"pages\":\"1-25\"},\"PeriodicalIF\":0.0,\"publicationDate\":\"2023-04-30\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10148754/pdf/\",\"citationCount\":\"2\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s41701-023-00143-0\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s41701-023-00143-0","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Strategies for the Analysis of Large Social Media Corpora: Sampling and Keyword Extraction Methods.
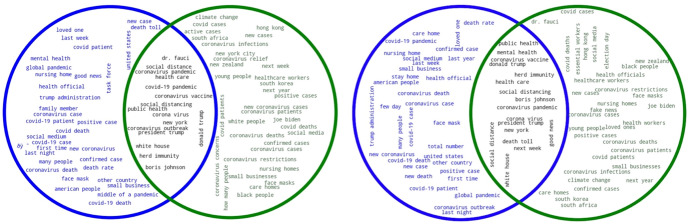
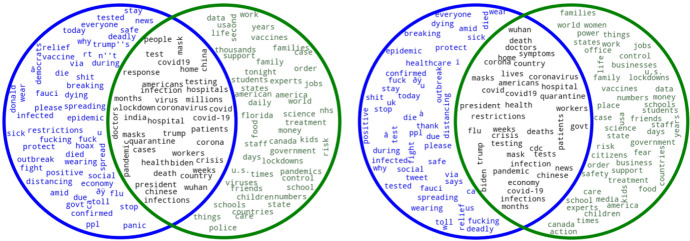
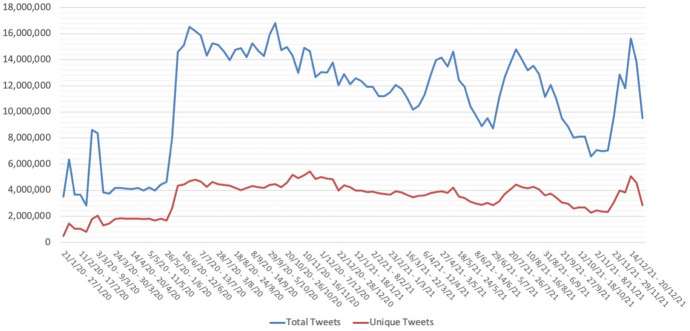
In the context of the COVID-19 pandemic, social media platforms such as Twitter have been of great importance for users to exchange news, ideas, and perceptions. Researchers from fields such as discourse analysis and the social sciences have resorted to this content to explore public opinion and stance on this topic, and they have tried to gather information through the compilation of large-scale corpora. However, the size of such corpora is both an advantage and a drawback, as simple text retrieval techniques and tools may prove to be impractical or altogether incapable of handling such masses of data. This study provides methodological and practical cues on how to manage the contents of a large-scale social media corpus such as Chen et al. (JMIR Public Health Surveill 6(2):e19273, 2020) COVID-19 corpus. We compare and evaluate, in terms of efficiency and efficacy, available methods to handle such a large corpus. First, we compare different sample sizes to assess whether it is possible to achieve similar results despite the size difference and evaluate sampling methods following a specific data management approach to storing the original corpus. Second, we examine two keyword extraction methodologies commonly used to obtain a compact representation of the main subject and topics of a text: the traditional method used in corpus linguistics, which compares word frequencies using a reference corpus, and graph-based techniques as developed in Natural Language Processing tasks. The methods and strategies discussed in this study enable valuable quantitative and qualitative analyses of an otherwise intractable mass of social media data.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


