Johannes Langguth, Daniel Thilo Schroeder, Petra Filkuková, Stefan Brenner, Jesper Phillips, Konstantin Pogorelov
{"title":"COCO:新冠肺炎阴谋论的注释推特数据集。","authors":"Johannes Langguth, Daniel Thilo Schroeder, Petra Filkuková, Stefan Brenner, Jesper Phillips, Konstantin Pogorelov","doi":"10.1007/s42001-023-00200-3","DOIUrl":null,"url":null,"abstract":"<p><p>The COVID-19 pandemic has been accompanied by a surge of misinformation on social media which covered a wide range of different topics and contained many competing narratives, including conspiracy theories. To study such conspiracy theories, we created a dataset of 3495 tweets with manual labeling of the stance of each tweet w.r.t. 12 different conspiracy topics. The dataset thus contains almost 42,000 labels, each of which determined by majority among three expert annotators. The dataset was selected from COVID-19 related Twitter data spanning from January 2020 to June 2021 using a list of 54 keywords. The dataset can be used to train machine learning based classifiers for both stance and topic detection, either individually or simultaneously. BERT was used successfully for the combined task. The dataset can also be used to further study the prevalence of different conspiracy narratives. To this end we qualitatively analyze the tweets, discussing the structure of conspiracy narratives that are frequently found in the dataset. Furthermore, we illustrate the interconnection between the conspiracy categories as well as the keywords.</p>","PeriodicalId":29946,"journal":{"name":"Journal of Computational Social Science","volume":" ","pages":"1-42"},"PeriodicalIF":2.3000,"publicationDate":"2023-04-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10071453/pdf/","citationCount":"1","resultStr":"{\"title\":\"COCO: an annotated Twitter dataset of COVID-19 conspiracy theories.\",\"authors\":\"Johannes Langguth, Daniel Thilo Schroeder, Petra Filkuková, Stefan Brenner, Jesper Phillips, Konstantin Pogorelov\",\"doi\":\"10.1007/s42001-023-00200-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>The COVID-19 pandemic has been accompanied by a surge of misinformation on social media which covered a wide range of different topics and contained many competing narratives, including conspiracy theories. To study such conspiracy theories, we created a dataset of 3495 tweets with manual labeling of the stance of each tweet w.r.t. 12 different conspiracy topics. The dataset thus contains almost 42,000 labels, each of which determined by majority among three expert annotators. The dataset was selected from COVID-19 related Twitter data spanning from January 2020 to June 2021 using a list of 54 keywords. The dataset can be used to train machine learning based classifiers for both stance and topic detection, either individually or simultaneously. BERT was used successfully for the combined task. The dataset can also be used to further study the prevalence of different conspiracy narratives. To this end we qualitatively analyze the tweets, discussing the structure of conspiracy narratives that are frequently found in the dataset. Furthermore, we illustrate the interconnection between the conspiracy categories as well as the keywords.</p>\",\"PeriodicalId\":29946,\"journal\":{\"name\":\"Journal of Computational Social Science\",\"volume\":\" \",\"pages\":\"1-42\"},\"PeriodicalIF\":2.3000,\"publicationDate\":\"2023-04-04\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10071453/pdf/\",\"citationCount\":\"1\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Computational Social Science\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s42001-023-00200-3\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"SOCIAL SCIENCES, MATHEMATICAL METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Computational Social Science","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s42001-023-00200-3","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"SOCIAL SCIENCES, MATHEMATICAL METHODS","Score":null,"Total":0}
COCO: an annotated Twitter dataset of COVID-19 conspiracy theories.
The COVID-19 pandemic has been accompanied by a surge of misinformation on social media which covered a wide range of different topics and contained many competing narratives, including conspiracy theories. To study such conspiracy theories, we created a dataset of 3495 tweets with manual labeling of the stance of each tweet w.r.t. 12 different conspiracy topics. The dataset thus contains almost 42,000 labels, each of which determined by majority among three expert annotators. The dataset was selected from COVID-19 related Twitter data spanning from January 2020 to June 2021 using a list of 54 keywords. The dataset can be used to train machine learning based classifiers for both stance and topic detection, either individually or simultaneously. BERT was used successfully for the combined task. The dataset can also be used to further study the prevalence of different conspiracy narratives. To this end we qualitatively analyze the tweets, discussing the structure of conspiracy narratives that are frequently found in the dataset. Furthermore, we illustrate the interconnection between the conspiracy categories as well as the keywords.
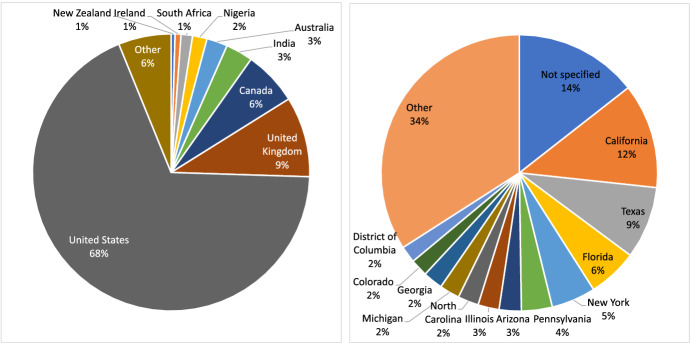
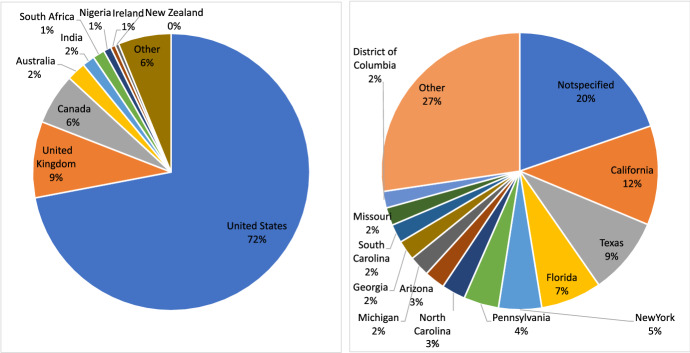
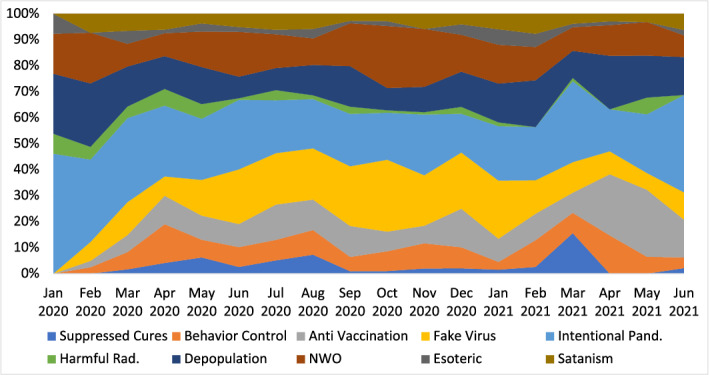

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


