Mattias Wahde, Marco L Della Vedova, Marco Virgolin, Minerva Suvanto
{"title":"一种可解释的口语转录本和书面文本自动分类方法。","authors":"Mattias Wahde, Marco L Della Vedova, Marco Virgolin, Minerva Suvanto","doi":"10.1007/s12065-023-00851-1","DOIUrl":null,"url":null,"abstract":"<p><p>We investigate the differences between spoken language (in the form of radio show transcripts) and written language (Wikipedia articles) in the context of text classification. We present a novel, interpretable method for text classification, involving a linear classifier using a large set of <math><mrow><mi>n</mi><mo>-</mo></mrow></math>gram features, and apply it to a newly generated data set with sentences originating either from spoken transcripts or written text. Our classifier reaches an accuracy less than 0.02 below that of a commonly used classifier (DistilBERT) based on deep neural networks (DNNs). Moreover, our classifier has an integrated measure of confidence, for assessing the reliability of a given classification. An online tool is provided for demonstrating our classifier, particularly its interpretable nature, which is a crucial feature in classification tasks involving high-stakes decision-making. We also study the capability of DistilBERT to carry out fill-in-the-blank tasks in either spoken or written text, and find it to perform similarly in both cases. Our main conclusion is that, with careful improvements, the performance gap between classical methods and DNN-based methods may be reduced significantly, such that the choice of classification method comes down to the need (if any) for interpretability.</p>","PeriodicalId":46237,"journal":{"name":"Evolutionary Intelligence","volume":" ","pages":"1-13"},"PeriodicalIF":2.6000,"publicationDate":"2023-05-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10157555/pdf/","citationCount":"0","resultStr":"{\"title\":\"An interpretable method for automated classification of spoken transcripts and written text.\",\"authors\":\"Mattias Wahde, Marco L Della Vedova, Marco Virgolin, Minerva Suvanto\",\"doi\":\"10.1007/s12065-023-00851-1\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>We investigate the differences between spoken language (in the form of radio show transcripts) and written language (Wikipedia articles) in the context of text classification. We present a novel, interpretable method for text classification, involving a linear classifier using a large set of <math><mrow><mi>n</mi><mo>-</mo></mrow></math>gram features, and apply it to a newly generated data set with sentences originating either from spoken transcripts or written text. Our classifier reaches an accuracy less than 0.02 below that of a commonly used classifier (DistilBERT) based on deep neural networks (DNNs). Moreover, our classifier has an integrated measure of confidence, for assessing the reliability of a given classification. An online tool is provided for demonstrating our classifier, particularly its interpretable nature, which is a crucial feature in classification tasks involving high-stakes decision-making. We also study the capability of DistilBERT to carry out fill-in-the-blank tasks in either spoken or written text, and find it to perform similarly in both cases. Our main conclusion is that, with careful improvements, the performance gap between classical methods and DNN-based methods may be reduced significantly, such that the choice of classification method comes down to the need (if any) for interpretability.</p>\",\"PeriodicalId\":46237,\"journal\":{\"name\":\"Evolutionary Intelligence\",\"volume\":\" \",\"pages\":\"1-13\"},\"PeriodicalIF\":2.6000,\"publicationDate\":\"2023-05-04\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10157555/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Evolutionary Intelligence\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s12065-023-00851-1\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Evolutionary Intelligence","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s12065-023-00851-1","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
An interpretable method for automated classification of spoken transcripts and written text.
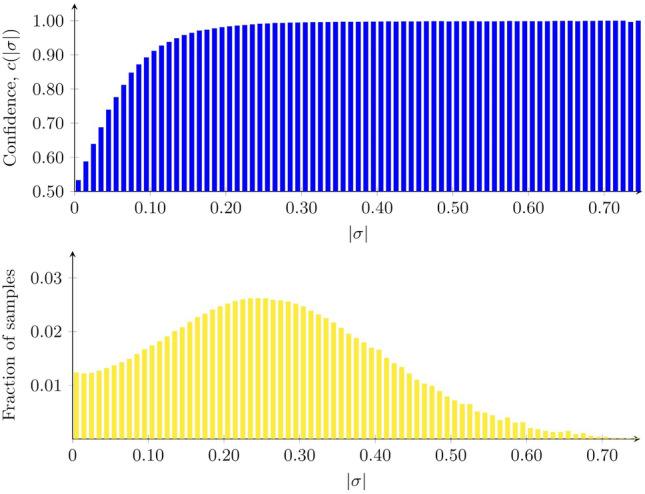
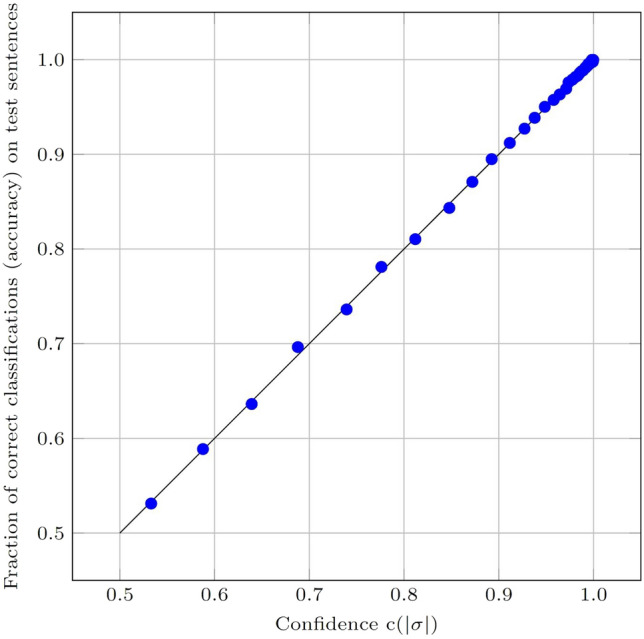
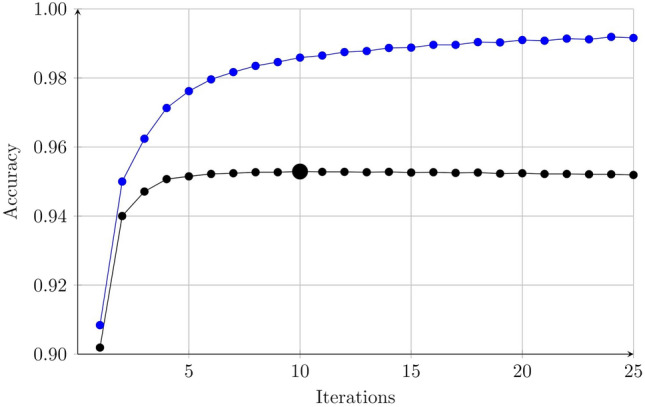
We investigate the differences between spoken language (in the form of radio show transcripts) and written language (Wikipedia articles) in the context of text classification. We present a novel, interpretable method for text classification, involving a linear classifier using a large set of gram features, and apply it to a newly generated data set with sentences originating either from spoken transcripts or written text. Our classifier reaches an accuracy less than 0.02 below that of a commonly used classifier (DistilBERT) based on deep neural networks (DNNs). Moreover, our classifier has an integrated measure of confidence, for assessing the reliability of a given classification. An online tool is provided for demonstrating our classifier, particularly its interpretable nature, which is a crucial feature in classification tasks involving high-stakes decision-making. We also study the capability of DistilBERT to carry out fill-in-the-blank tasks in either spoken or written text, and find it to perform similarly in both cases. Our main conclusion is that, with careful improvements, the performance gap between classical methods and DNN-based methods may be reduced significantly, such that the choice of classification method comes down to the need (if any) for interpretability.
期刊介绍:
This Journal provides an international forum for the timely publication and dissemination of foundational and applied research in the domain of Evolutionary Intelligence. The spectrum of emerging fields in contemporary artificial intelligence, including Big Data, Deep Learning, Computational Neuroscience bridged with evolutionary computing and other population-based search methods constitute the flag of Evolutionary Intelligence Journal.Topics of interest for Evolutionary Intelligence refer to different aspects of evolutionary models of computation empowered with intelligence-based approaches, including but not limited to architectures, model optimization and tuning, machine learning algorithms, life inspired adaptive algorithms, swarm-oriented strategies, high performance computing, massive data processing, with applications to domains like computer vision, image processing, simulation, robotics, computational finance, media, internet of things, medicine, bioinformatics, smart cities, and similar. Surveys outlining the state of art in specific subfields and applications are welcome.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


