Protiva Rahman, Cheng Ye, Kathleen F Mittendorf, Michele Lenoue-Newton, Christine Micheel, Jan Wolber, Travis Osterman, Daniel Fabbri
{"title":"电子健康记录中检查点抑制剂诱导结肠炎病例的加速管理。","authors":"Protiva Rahman, Cheng Ye, Kathleen F Mittendorf, Michele Lenoue-Newton, Christine Micheel, Jan Wolber, Travis Osterman, Daniel Fabbri","doi":"10.1093/jamiaopen/ooad017","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>Automatically identifying patients at risk of immune checkpoint inhibitor (ICI)-induced colitis allows physicians to improve patientcare. However, predictive models require training data curated from electronic health records (EHR). Our objective is to automatically identify notes documenting ICI-colitis cases to accelerate data curation.</p><p><strong>Materials and methods: </strong>We present a data pipeline to automatically identify ICI-colitis from EHR notes, accelerating chart review. The pipeline relies on BERT, a state-of-the-art natural language processing (NLP) model. The first stage of the pipeline segments long notes using keywords identified through a logistic classifier and applies BERT to identify ICI-colitis notes. The next stage uses a second BERT model tuned to identify false positive notes and remove notes that were likely positive for mentioning colitis as a side-effect. The final stage further accelerates curation by highlighting the colitis-relevant portions of notes. Specifically, we use BERT's attention scores to find high-density regions describing colitis.</p><p><strong>Results: </strong>The overall pipeline identified colitis notes with 84% precision and reduced the curator note review load by 75%. The segment BERT classifier had a high recall of 0.98, which is crucial to identify the low incidence (<10%) of colitis.</p><p><strong>Discussion: </strong>Curation from EHR notes is a burdensome task, especially when the curation topic is complicated. Methods described in this work are not only useful for ICI colitis but can also be adapted for other domains.</p><p><strong>Conclusion: </strong>Our extraction pipeline reduces manual note review load and makes EHR data more accessible for research.</p>","PeriodicalId":36278,"journal":{"name":"JAMIA Open","volume":"6 1","pages":"ooad017"},"PeriodicalIF":2.5000,"publicationDate":"2023-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/4f/2b/ooad017.PMC10066800.pdf","citationCount":"0","resultStr":"{\"title\":\"Accelerated curation of checkpoint inhibitor-induced colitis cases from electronic health records.\",\"authors\":\"Protiva Rahman, Cheng Ye, Kathleen F Mittendorf, Michele Lenoue-Newton, Christine Micheel, Jan Wolber, Travis Osterman, Daniel Fabbri\",\"doi\":\"10.1093/jamiaopen/ooad017\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objective: </strong>Automatically identifying patients at risk of immune checkpoint inhibitor (ICI)-induced colitis allows physicians to improve patientcare. However, predictive models require training data curated from electronic health records (EHR). Our objective is to automatically identify notes documenting ICI-colitis cases to accelerate data curation.</p><p><strong>Materials and methods: </strong>We present a data pipeline to automatically identify ICI-colitis from EHR notes, accelerating chart review. The pipeline relies on BERT, a state-of-the-art natural language processing (NLP) model. The first stage of the pipeline segments long notes using keywords identified through a logistic classifier and applies BERT to identify ICI-colitis notes. The next stage uses a second BERT model tuned to identify false positive notes and remove notes that were likely positive for mentioning colitis as a side-effect. The final stage further accelerates curation by highlighting the colitis-relevant portions of notes. Specifically, we use BERT's attention scores to find high-density regions describing colitis.</p><p><strong>Results: </strong>The overall pipeline identified colitis notes with 84% precision and reduced the curator note review load by 75%. The segment BERT classifier had a high recall of 0.98, which is crucial to identify the low incidence (<10%) of colitis.</p><p><strong>Discussion: </strong>Curation from EHR notes is a burdensome task, especially when the curation topic is complicated. Methods described in this work are not only useful for ICI colitis but can also be adapted for other domains.</p><p><strong>Conclusion: </strong>Our extraction pipeline reduces manual note review load and makes EHR data more accessible for research.</p>\",\"PeriodicalId\":36278,\"journal\":{\"name\":\"JAMIA Open\",\"volume\":\"6 1\",\"pages\":\"ooad017\"},\"PeriodicalIF\":2.5000,\"publicationDate\":\"2023-04-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/4f/2b/ooad017.PMC10066800.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JAMIA Open\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/jamiaopen/ooad017\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAMIA Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/jamiaopen/ooad017","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Accelerated curation of checkpoint inhibitor-induced colitis cases from electronic health records.
Objective: Automatically identifying patients at risk of immune checkpoint inhibitor (ICI)-induced colitis allows physicians to improve patientcare. However, predictive models require training data curated from electronic health records (EHR). Our objective is to automatically identify notes documenting ICI-colitis cases to accelerate data curation.
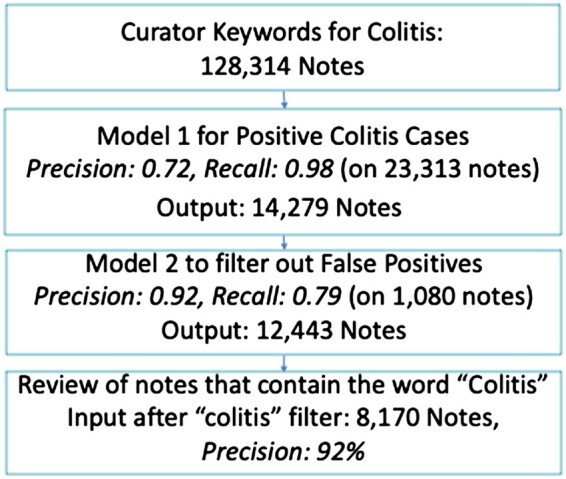
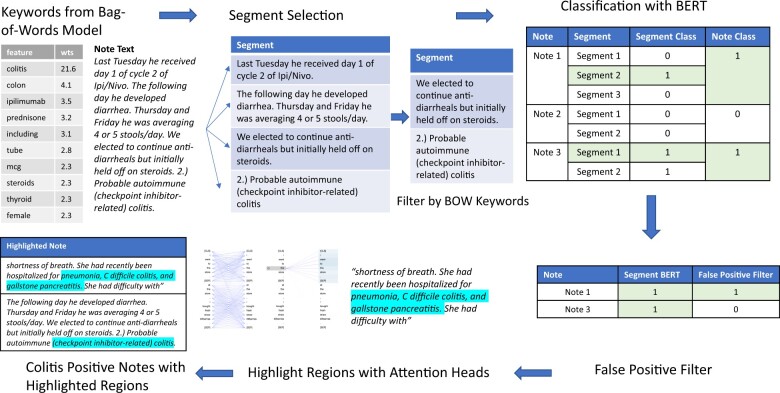
Materials and methods: We present a data pipeline to automatically identify ICI-colitis from EHR notes, accelerating chart review. The pipeline relies on BERT, a state-of-the-art natural language processing (NLP) model. The first stage of the pipeline segments long notes using keywords identified through a logistic classifier and applies BERT to identify ICI-colitis notes. The next stage uses a second BERT model tuned to identify false positive notes and remove notes that were likely positive for mentioning colitis as a side-effect. The final stage further accelerates curation by highlighting the colitis-relevant portions of notes. Specifically, we use BERT's attention scores to find high-density regions describing colitis.
Results: The overall pipeline identified colitis notes with 84% precision and reduced the curator note review load by 75%. The segment BERT classifier had a high recall of 0.98, which is crucial to identify the low incidence (<10%) of colitis.
Discussion: Curation from EHR notes is a burdensome task, especially when the curation topic is complicated. Methods described in this work are not only useful for ICI colitis but can also be adapted for other domains.
Conclusion: Our extraction pipeline reduces manual note review load and makes EHR data more accessible for research.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


