W L Boyajian, J Clausen, L M Trenkwalder, V Dunjko, H J Briegel
{"title":"论马尔可夫决策过程中基于投影模拟的强化学习的收敛性","authors":"W L Boyajian, J Clausen, L M Trenkwalder, V Dunjko, H J Briegel","doi":"10.1007/s42484-020-00023-9","DOIUrl":null,"url":null,"abstract":"<p><p>In recent years, the interest in leveraging quantum effects for enhancing machine learning tasks has significantly increased. Many algorithms speeding up supervised and unsupervised learning were established. The first framework in which ways to exploit quantum resources specifically for the broader context of reinforcement learning were found is projective simulation. Projective simulation presents an agent-based reinforcement learning approach designed in a manner which may support quantum walk-based speedups. Although classical variants of projective simulation have been benchmarked against common reinforcement learning algorithms, very few formal theoretical analyses have been provided for its performance in standard learning scenarios. In this paper, we provide a detailed formal discussion of the properties of this model. Specifically, we prove that one version of the projective simulation model, understood as a reinforcement learning approach, converges to optimal behavior in a large class of Markov decision processes. This proof shows that a physically inspired approach to reinforcement learning can guarantee to converge.</p>","PeriodicalId":29924,"journal":{"name":"Quantum Machine Intelligence","volume":"2 2","pages":"13"},"PeriodicalIF":4.4000,"publicationDate":"2020-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7644479/pdf/","citationCount":"0","resultStr":"{\"title\":\"On the convergence of projective-simulation-based reinforcement learning in Markov decision processes.\",\"authors\":\"W L Boyajian, J Clausen, L M Trenkwalder, V Dunjko, H J Briegel\",\"doi\":\"10.1007/s42484-020-00023-9\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>In recent years, the interest in leveraging quantum effects for enhancing machine learning tasks has significantly increased. Many algorithms speeding up supervised and unsupervised learning were established. The first framework in which ways to exploit quantum resources specifically for the broader context of reinforcement learning were found is projective simulation. Projective simulation presents an agent-based reinforcement learning approach designed in a manner which may support quantum walk-based speedups. Although classical variants of projective simulation have been benchmarked against common reinforcement learning algorithms, very few formal theoretical analyses have been provided for its performance in standard learning scenarios. In this paper, we provide a detailed formal discussion of the properties of this model. Specifically, we prove that one version of the projective simulation model, understood as a reinforcement learning approach, converges to optimal behavior in a large class of Markov decision processes. This proof shows that a physically inspired approach to reinforcement learning can guarantee to converge.</p>\",\"PeriodicalId\":29924,\"journal\":{\"name\":\"Quantum Machine Intelligence\",\"volume\":\"2 2\",\"pages\":\"13\"},\"PeriodicalIF\":4.4000,\"publicationDate\":\"2020-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7644479/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Quantum Machine Intelligence\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s42484-020-00023-9\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2020/11/5 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Quantum Machine Intelligence","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s42484-020-00023-9","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2020/11/5 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
On the convergence of projective-simulation-based reinforcement learning in Markov decision processes.
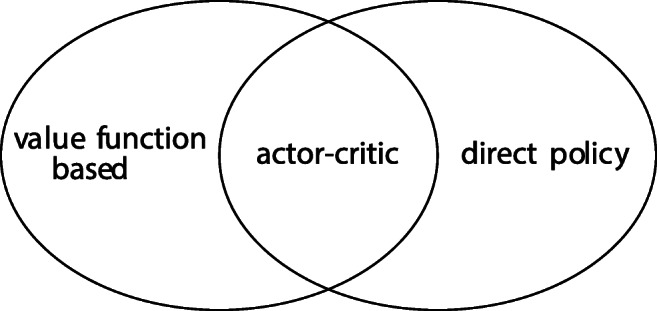
In recent years, the interest in leveraging quantum effects for enhancing machine learning tasks has significantly increased. Many algorithms speeding up supervised and unsupervised learning were established. The first framework in which ways to exploit quantum resources specifically for the broader context of reinforcement learning were found is projective simulation. Projective simulation presents an agent-based reinforcement learning approach designed in a manner which may support quantum walk-based speedups. Although classical variants of projective simulation have been benchmarked against common reinforcement learning algorithms, very few formal theoretical analyses have been provided for its performance in standard learning scenarios. In this paper, we provide a detailed formal discussion of the properties of this model. Specifically, we prove that one version of the projective simulation model, understood as a reinforcement learning approach, converges to optimal behavior in a large class of Markov decision processes. This proof shows that a physically inspired approach to reinforcement learning can guarantee to converge.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


