{"title":"荷兰2019冠状病毒病新闻发布会上的演讲。","authors":"Daan Schueler, Maarten Marx","doi":"10.1007/s10579-022-09602-7","DOIUrl":null,"url":null,"abstract":"<p><p>An open source corpus of all Dutch COVID-19 Press Conferences with sentences annotated on the basis of John Searle's Speech Act taxonomy was created. It contains all 58 press conferences held between March 6 2020 and April 20 2021 and has 9.441 manually annotated sentences. Speech acts were annotated in a consistent manner, with a Krippendorff's alpha of .71. The corpus is easy to use and rich in metadata, with lexical, syntactic, discourse (speaker, question or answer) features and information on the type of regulations being present. We analyse the press conferences in terms of speech act usage, giving insight into the use of speech acts over time, the relation of speech act usage to real world phenomena, the general structure of the press conferences and the division of roles between speakers. Relations were found between speech act usage and the type of press conference (i.e. easing, tightening or neutral) as well as the number of hospital admissions. Speech act classes showed preferred locations within the press conferences, indicating a general structure. Distinct roles between speakers were identified. We also investigate the use of our set of labelled sentences for training a speech act classifier and achieve a reasonable accuracy of .73 and a mean reciprocal rank of .74 with the state of the art transformer RoBERTa model.</p><p><strong>Supplementary information: </strong>The online version of this article contains supplementary material available 10.1007/s10579-022-09602-7.</p>","PeriodicalId":49927,"journal":{"name":"Language Resources and Evaluation","volume":"57 2","pages":"869-892"},"PeriodicalIF":1.7000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9294846/pdf/","citationCount":"3","resultStr":"{\"title\":\"Speech acts in the Dutch COVID-19 Press Conferences.\",\"authors\":\"Daan Schueler, Maarten Marx\",\"doi\":\"10.1007/s10579-022-09602-7\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>An open source corpus of all Dutch COVID-19 Press Conferences with sentences annotated on the basis of John Searle's Speech Act taxonomy was created. It contains all 58 press conferences held between March 6 2020 and April 20 2021 and has 9.441 manually annotated sentences. Speech acts were annotated in a consistent manner, with a Krippendorff's alpha of .71. The corpus is easy to use and rich in metadata, with lexical, syntactic, discourse (speaker, question or answer) features and information on the type of regulations being present. We analyse the press conferences in terms of speech act usage, giving insight into the use of speech acts over time, the relation of speech act usage to real world phenomena, the general structure of the press conferences and the division of roles between speakers. Relations were found between speech act usage and the type of press conference (i.e. easing, tightening or neutral) as well as the number of hospital admissions. Speech act classes showed preferred locations within the press conferences, indicating a general structure. Distinct roles between speakers were identified. We also investigate the use of our set of labelled sentences for training a speech act classifier and achieve a reasonable accuracy of .73 and a mean reciprocal rank of .74 with the state of the art transformer RoBERTa model.</p><p><strong>Supplementary information: </strong>The online version of this article contains supplementary material available 10.1007/s10579-022-09602-7.</p>\",\"PeriodicalId\":49927,\"journal\":{\"name\":\"Language Resources and Evaluation\",\"volume\":\"57 2\",\"pages\":\"869-892\"},\"PeriodicalIF\":1.7000,\"publicationDate\":\"2023-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9294846/pdf/\",\"citationCount\":\"3\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Language Resources and Evaluation\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s10579-022-09602-7\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Language Resources and Evaluation","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10579-022-09602-7","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
Speech acts in the Dutch COVID-19 Press Conferences.
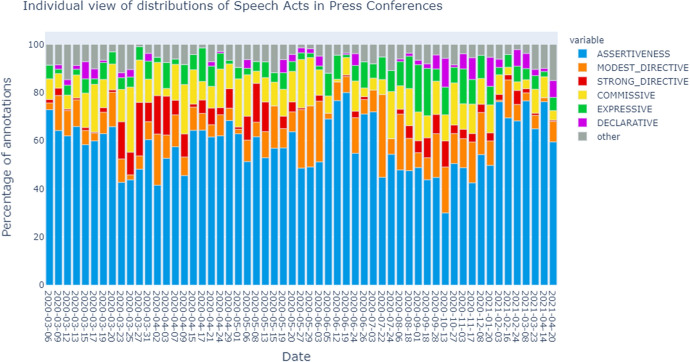
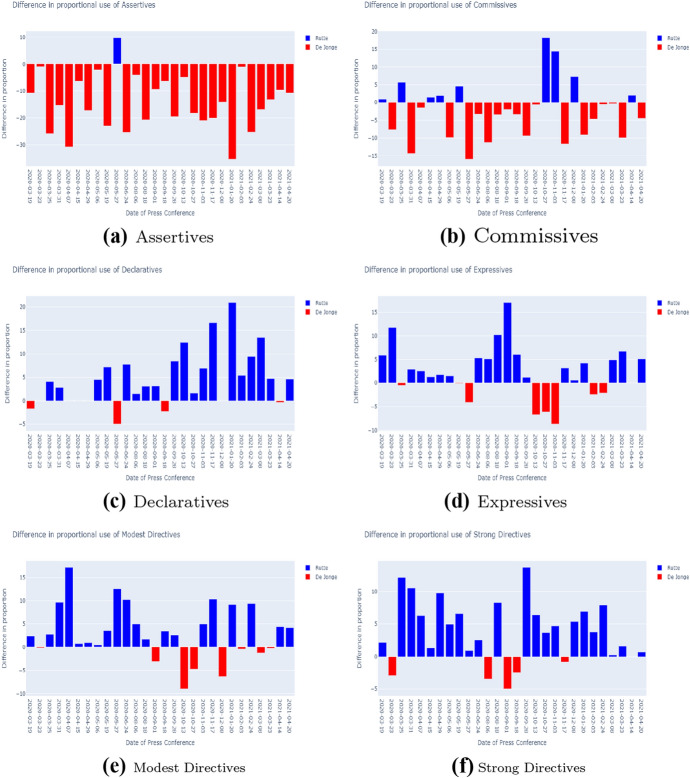
An open source corpus of all Dutch COVID-19 Press Conferences with sentences annotated on the basis of John Searle's Speech Act taxonomy was created. It contains all 58 press conferences held between March 6 2020 and April 20 2021 and has 9.441 manually annotated sentences. Speech acts were annotated in a consistent manner, with a Krippendorff's alpha of .71. The corpus is easy to use and rich in metadata, with lexical, syntactic, discourse (speaker, question or answer) features and information on the type of regulations being present. We analyse the press conferences in terms of speech act usage, giving insight into the use of speech acts over time, the relation of speech act usage to real world phenomena, the general structure of the press conferences and the division of roles between speakers. Relations were found between speech act usage and the type of press conference (i.e. easing, tightening or neutral) as well as the number of hospital admissions. Speech act classes showed preferred locations within the press conferences, indicating a general structure. Distinct roles between speakers were identified. We also investigate the use of our set of labelled sentences for training a speech act classifier and achieve a reasonable accuracy of .73 and a mean reciprocal rank of .74 with the state of the art transformer RoBERTa model.
Supplementary information: The online version of this article contains supplementary material available 10.1007/s10579-022-09602-7.
期刊介绍:
Language Resources and Evaluation is the first publication devoted to the acquisition, creation, annotation, and use of language resources, together with methods for evaluation of resources, technologies, and applications.
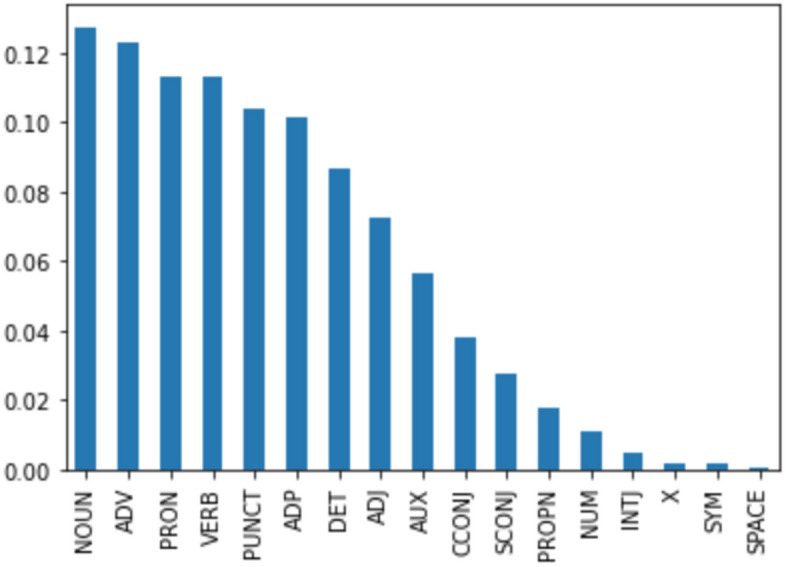
Language resources include language data and descriptions in machine readable form used to assist and augment language processing applications, such as written or spoken corpora and lexica, multimodal resources, grammars, terminology or domain specific databases and dictionaries, ontologies, multimedia databases, etc., as well as basic software tools for their acquisition, preparation, annotation, management, customization, and use.
Evaluation of language resources concerns assessing the state-of-the-art for a given technology, comparing different approaches to a given problem, assessing the availability of resources and technologies for a given application, benchmarking, and assessing system usability and user satisfaction.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


