Aaron Wendelboe, Ibrahim Saber, Justin Dvorak, Alys Adamski, Natalie Feland, Nimia Reyes, Karon Abe, Thomas Ortel, Gary Raskob
{"title":"探索使用自然语言处理支持全国性静脉血栓栓塞监测的适用性:模型评估研究。","authors":"Aaron Wendelboe, Ibrahim Saber, Justin Dvorak, Alys Adamski, Natalie Feland, Nimia Reyes, Karon Abe, Thomas Ortel, Gary Raskob","doi":"10.2196/36877","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Venous thromboembolism (VTE) is a preventable, common vascular disease that has been estimated to affect up to 900,000 people per year. It has been associated with risk factors such as recent surgery, cancer, and hospitalization. VTE surveillance for patient management and safety can be improved via natural language processing (NLP). NLP tools have the ability to access electronic medical records, identify patients that meet the VTE case definition, and subsequently enter the relevant information into a database for hospital review.</p><p><strong>Objective: </strong>We aimed to evaluate the performance of a VTE identification model of IDEAL-X (Information and Data Extraction Using Adaptive Learning; Emory University)-an NLP tool-in automatically classifying cases of VTE by \"reading\" unstructured text from diagnostic imaging records collected from 2012 to 2014.</p><p><strong>Methods: </strong>After accessing imaging records from pilot surveillance systems for VTE from Duke University and the University of Oklahoma Health Sciences Center (OUHSC), we used a VTE identification model of IDEAL-X to classify cases of VTE that had previously been manually classified. Experts reviewed the technicians' comments in each record to determine if a VTE event occurred. The performance measures calculated (with 95% CIs) were accuracy, sensitivity, specificity, and positive and negative predictive values. Chi-square tests of homogeneity were conducted to evaluate differences in performance measures by site, using a significance level of .05.</p><p><strong>Results: </strong>The VTE model of IDEAL-X \"read\" 1591 records from Duke University and 1487 records from the OUHSC, for a total of 3078 records. The combined performance measures were 93.7% accuracy (95% CI 93.7%-93.8%), 96.3% sensitivity (95% CI 96.2%-96.4%), 92% specificity (95% CI 91.9%-92%), an 89.1% positive predictive value (95% CI 89%-89.2%), and a 97.3% negative predictive value (95% CI 97.3%-97.4%). The sensitivity was higher at Duke University (97.9%, 95% CI 97.8%-98%) than at the OUHSC (93.3%, 95% CI 93.1%-93.4%; <i>P</i><.001), but the specificity was higher at the OUHSC (95.9%, 95% CI 95.8%-96%) than at Duke University (86.5%, 95% CI 86.4%-86.7%; <i>P</i><.001).</p><p><strong>Conclusions: </strong>The VTE model of IDEAL-X accurately classified cases of VTE from the pilot surveillance systems of two separate health systems in Durham, North Carolina, and Oklahoma City, Oklahoma. NLP is a promising tool for the design and implementation of an automated, cost-effective national surveillance system for VTE. Conducting public health surveillance at a national scale is important for measuring disease burden and the impact of prevention measures. We recommend additional studies to identify how integrating IDEAL-X in a medical record system could further automate the surveillance process.</p>","PeriodicalId":73552,"journal":{"name":"JMIR bioinformatics and biotechnology","volume":"3 1","pages":"e36877"},"PeriodicalIF":0.0000,"publicationDate":"2022-05-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10193259/pdf/","citationCount":"0","resultStr":"{\"title\":\"Exploring the Applicability of Using Natural Language Processing to Support Nationwide Venous Thromboembolism Surveillance: Model Evaluation Study.\",\"authors\":\"Aaron Wendelboe, Ibrahim Saber, Justin Dvorak, Alys Adamski, Natalie Feland, Nimia Reyes, Karon Abe, Thomas Ortel, Gary Raskob\",\"doi\":\"10.2196/36877\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Venous thromboembolism (VTE) is a preventable, common vascular disease that has been estimated to affect up to 900,000 people per year. It has been associated with risk factors such as recent surgery, cancer, and hospitalization. VTE surveillance for patient management and safety can be improved via natural language processing (NLP). NLP tools have the ability to access electronic medical records, identify patients that meet the VTE case definition, and subsequently enter the relevant information into a database for hospital review.</p><p><strong>Objective: </strong>We aimed to evaluate the performance of a VTE identification model of IDEAL-X (Information and Data Extraction Using Adaptive Learning; Emory University)-an NLP tool-in automatically classifying cases of VTE by \\\"reading\\\" unstructured text from diagnostic imaging records collected from 2012 to 2014.</p><p><strong>Methods: </strong>After accessing imaging records from pilot surveillance systems for VTE from Duke University and the University of Oklahoma Health Sciences Center (OUHSC), we used a VTE identification model of IDEAL-X to classify cases of VTE that had previously been manually classified. Experts reviewed the technicians' comments in each record to determine if a VTE event occurred. The performance measures calculated (with 95% CIs) were accuracy, sensitivity, specificity, and positive and negative predictive values. Chi-square tests of homogeneity were conducted to evaluate differences in performance measures by site, using a significance level of .05.</p><p><strong>Results: </strong>The VTE model of IDEAL-X \\\"read\\\" 1591 records from Duke University and 1487 records from the OUHSC, for a total of 3078 records. The combined performance measures were 93.7% accuracy (95% CI 93.7%-93.8%), 96.3% sensitivity (95% CI 96.2%-96.4%), 92% specificity (95% CI 91.9%-92%), an 89.1% positive predictive value (95% CI 89%-89.2%), and a 97.3% negative predictive value (95% CI 97.3%-97.4%). The sensitivity was higher at Duke University (97.9%, 95% CI 97.8%-98%) than at the OUHSC (93.3%, 95% CI 93.1%-93.4%; <i>P</i><.001), but the specificity was higher at the OUHSC (95.9%, 95% CI 95.8%-96%) than at Duke University (86.5%, 95% CI 86.4%-86.7%; <i>P</i><.001).</p><p><strong>Conclusions: </strong>The VTE model of IDEAL-X accurately classified cases of VTE from the pilot surveillance systems of two separate health systems in Durham, North Carolina, and Oklahoma City, Oklahoma. NLP is a promising tool for the design and implementation of an automated, cost-effective national surveillance system for VTE. Conducting public health surveillance at a national scale is important for measuring disease burden and the impact of prevention measures. We recommend additional studies to identify how integrating IDEAL-X in a medical record system could further automate the surveillance process.</p>\",\"PeriodicalId\":73552,\"journal\":{\"name\":\"JMIR bioinformatics and biotechnology\",\"volume\":\"3 1\",\"pages\":\"e36877\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2022-05-08\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10193259/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR bioinformatics and biotechnology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/36877\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR bioinformatics and biotechnology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/36877","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Exploring the Applicability of Using Natural Language Processing to Support Nationwide Venous Thromboembolism Surveillance: Model Evaluation Study.
Background: Venous thromboembolism (VTE) is a preventable, common vascular disease that has been estimated to affect up to 900,000 people per year. It has been associated with risk factors such as recent surgery, cancer, and hospitalization. VTE surveillance for patient management and safety can be improved via natural language processing (NLP). NLP tools have the ability to access electronic medical records, identify patients that meet the VTE case definition, and subsequently enter the relevant information into a database for hospital review.
Objective: We aimed to evaluate the performance of a VTE identification model of IDEAL-X (Information and Data Extraction Using Adaptive Learning; Emory University)-an NLP tool-in automatically classifying cases of VTE by "reading" unstructured text from diagnostic imaging records collected from 2012 to 2014.
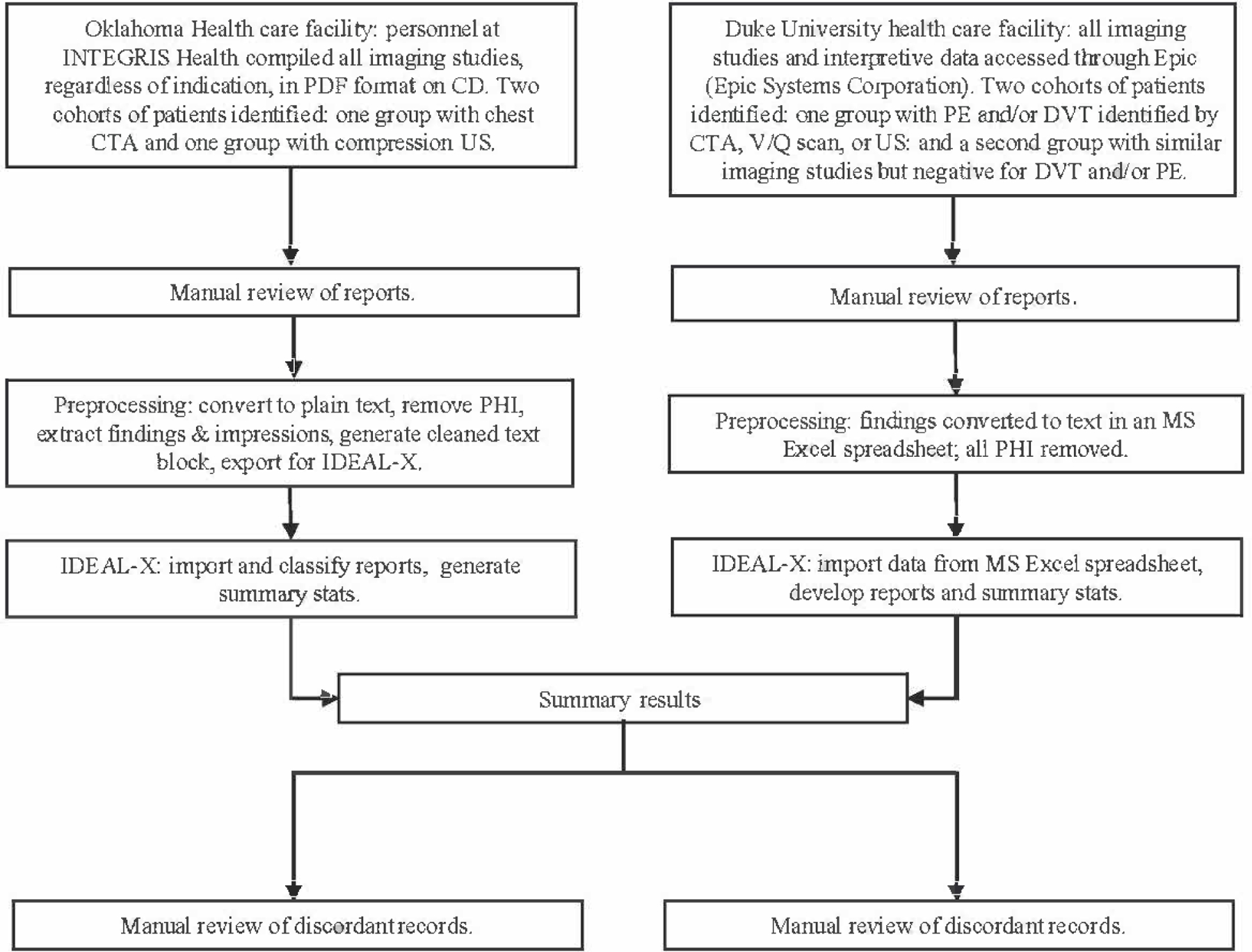
Methods: After accessing imaging records from pilot surveillance systems for VTE from Duke University and the University of Oklahoma Health Sciences Center (OUHSC), we used a VTE identification model of IDEAL-X to classify cases of VTE that had previously been manually classified. Experts reviewed the technicians' comments in each record to determine if a VTE event occurred. The performance measures calculated (with 95% CIs) were accuracy, sensitivity, specificity, and positive and negative predictive values. Chi-square tests of homogeneity were conducted to evaluate differences in performance measures by site, using a significance level of .05.
Results: The VTE model of IDEAL-X "read" 1591 records from Duke University and 1487 records from the OUHSC, for a total of 3078 records. The combined performance measures were 93.7% accuracy (95% CI 93.7%-93.8%), 96.3% sensitivity (95% CI 96.2%-96.4%), 92% specificity (95% CI 91.9%-92%), an 89.1% positive predictive value (95% CI 89%-89.2%), and a 97.3% negative predictive value (95% CI 97.3%-97.4%). The sensitivity was higher at Duke University (97.9%, 95% CI 97.8%-98%) than at the OUHSC (93.3%, 95% CI 93.1%-93.4%; P<.001), but the specificity was higher at the OUHSC (95.9%, 95% CI 95.8%-96%) than at Duke University (86.5%, 95% CI 86.4%-86.7%; P<.001).
Conclusions: The VTE model of IDEAL-X accurately classified cases of VTE from the pilot surveillance systems of two separate health systems in Durham, North Carolina, and Oklahoma City, Oklahoma. NLP is a promising tool for the design and implementation of an automated, cost-effective national surveillance system for VTE. Conducting public health surveillance at a national scale is important for measuring disease burden and the impact of prevention measures. We recommend additional studies to identify how integrating IDEAL-X in a medical record system could further automate the surveillance process.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


