{"title":"使用机器学习预测泼尼松龙剂量校正。","authors":"Hiroyasu Sato, Yoshinobu Kimura, Masahiro Ohba, Yoshiaki Ara, Susumu Wakabayashi, Hiroaki Watanabe","doi":"10.1007/s41666-023-00128-3","DOIUrl":null,"url":null,"abstract":"<p><p>Wrong dose, a common prescription error, can cause serious patient harm, especially in the case of high-risk drugs like oral corticosteroids. This study aims to build a machine learning model to predict dose-related prescription modifications for oral prednisolone tablets (i.e., highly imbalanced data with very few positive cases). Prescription data were obtained from the electronic medical records at a single institute. Cluster analysis classified the clinical departments into six clusters with similar patterns of prednisolone prescription. Two patterns of training datasets were created with/without preprocessing by the SMOTE method. Five ML models (SVM, KNN, GB, RF, and BRF) and logistic regression (LR) models were constructed by Python. The model was internally validated by five-fold stratified cross-validation and was validated with a 30% holdout test dataset. Eighty-two thousand five hundred fifty-three prescribing data for prednisolone tablets containing 135 dose-corrected positive cases were obtained. In the original dataset (without SMOTE), only the BRF model showed a good performance (in test dataset, ROC-AUC:0.917, recall: 0.951). In the training dataset preprocessed by SMOTE, performance was improved on all models. The highest performance models with SMOTE were SVM (in test dataset, ROC-AUC: 0.820, recall: 0.659) and BRF (ROC-AUC: 0.814, recall: 0.634). Although the prescribing data for dose-related collection are highly imbalanced, various techniques such as the following have allowed us to build high-performance prediction models: data preprocessing by SMOTE, stratified cross-validation, and BRF classifier corresponding to imbalanced data. ML is useful in complicated dose audits such as oral prednisolone.</p><p><strong>Supplementary information: </strong>The online version contains supplementary material available at 10.1007/s41666-023-00128-3.</p>","PeriodicalId":36444,"journal":{"name":"Journal of Healthcare Informatics Research","volume":"7 1","pages":"84-103"},"PeriodicalIF":5.9000,"publicationDate":"2023-03-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9995628/pdf/","citationCount":"0","resultStr":"{\"title\":\"Prediction of Prednisolone Dose Correction Using Machine Learning.\",\"authors\":\"Hiroyasu Sato, Yoshinobu Kimura, Masahiro Ohba, Yoshiaki Ara, Susumu Wakabayashi, Hiroaki Watanabe\",\"doi\":\"10.1007/s41666-023-00128-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Wrong dose, a common prescription error, can cause serious patient harm, especially in the case of high-risk drugs like oral corticosteroids. This study aims to build a machine learning model to predict dose-related prescription modifications for oral prednisolone tablets (i.e., highly imbalanced data with very few positive cases). Prescription data were obtained from the electronic medical records at a single institute. Cluster analysis classified the clinical departments into six clusters with similar patterns of prednisolone prescription. Two patterns of training datasets were created with/without preprocessing by the SMOTE method. Five ML models (SVM, KNN, GB, RF, and BRF) and logistic regression (LR) models were constructed by Python. The model was internally validated by five-fold stratified cross-validation and was validated with a 30% holdout test dataset. Eighty-two thousand five hundred fifty-three prescribing data for prednisolone tablets containing 135 dose-corrected positive cases were obtained. In the original dataset (without SMOTE), only the BRF model showed a good performance (in test dataset, ROC-AUC:0.917, recall: 0.951). In the training dataset preprocessed by SMOTE, performance was improved on all models. The highest performance models with SMOTE were SVM (in test dataset, ROC-AUC: 0.820, recall: 0.659) and BRF (ROC-AUC: 0.814, recall: 0.634). Although the prescribing data for dose-related collection are highly imbalanced, various techniques such as the following have allowed us to build high-performance prediction models: data preprocessing by SMOTE, stratified cross-validation, and BRF classifier corresponding to imbalanced data. ML is useful in complicated dose audits such as oral prednisolone.</p><p><strong>Supplementary information: </strong>The online version contains supplementary material available at 10.1007/s41666-023-00128-3.</p>\",\"PeriodicalId\":36444,\"journal\":{\"name\":\"Journal of Healthcare Informatics Research\",\"volume\":\"7 1\",\"pages\":\"84-103\"},\"PeriodicalIF\":5.9000,\"publicationDate\":\"2023-03-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9995628/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Healthcare Informatics Research\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s41666-023-00128-3\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"Computer Science\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Healthcare Informatics Research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s41666-023-00128-3","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"Computer Science","Score":null,"Total":0}
Prediction of Prednisolone Dose Correction Using Machine Learning.
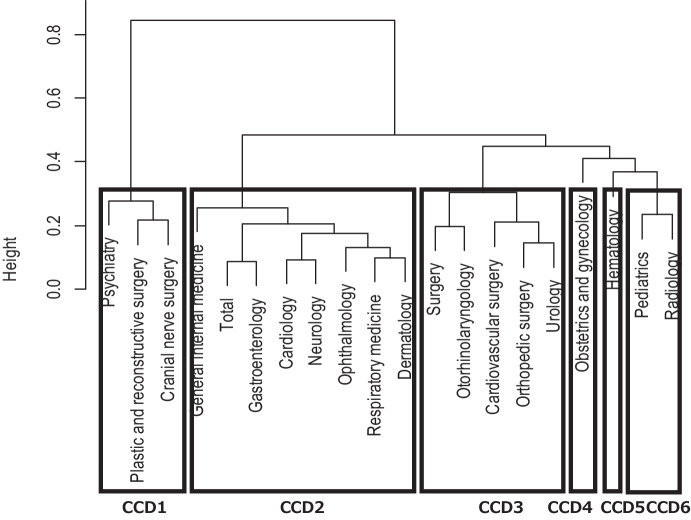
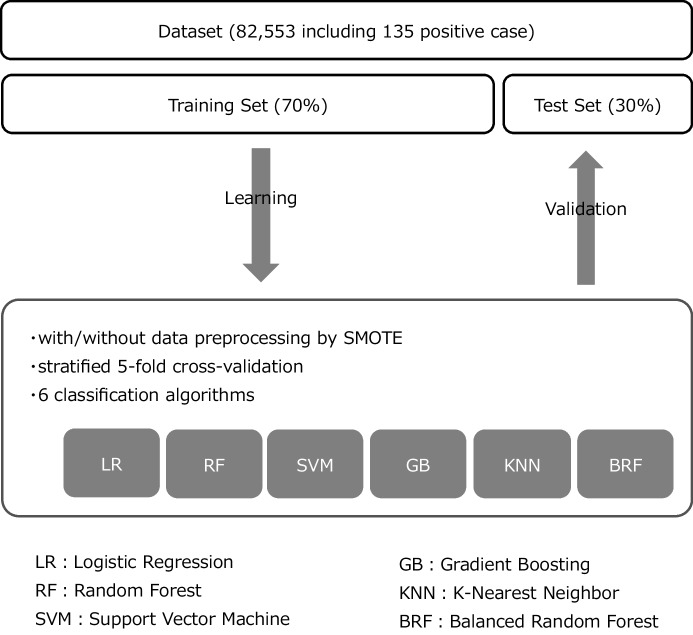
Wrong dose, a common prescription error, can cause serious patient harm, especially in the case of high-risk drugs like oral corticosteroids. This study aims to build a machine learning model to predict dose-related prescription modifications for oral prednisolone tablets (i.e., highly imbalanced data with very few positive cases). Prescription data were obtained from the electronic medical records at a single institute. Cluster analysis classified the clinical departments into six clusters with similar patterns of prednisolone prescription. Two patterns of training datasets were created with/without preprocessing by the SMOTE method. Five ML models (SVM, KNN, GB, RF, and BRF) and logistic regression (LR) models were constructed by Python. The model was internally validated by five-fold stratified cross-validation and was validated with a 30% holdout test dataset. Eighty-two thousand five hundred fifty-three prescribing data for prednisolone tablets containing 135 dose-corrected positive cases were obtained. In the original dataset (without SMOTE), only the BRF model showed a good performance (in test dataset, ROC-AUC:0.917, recall: 0.951). In the training dataset preprocessed by SMOTE, performance was improved on all models. The highest performance models with SMOTE were SVM (in test dataset, ROC-AUC: 0.820, recall: 0.659) and BRF (ROC-AUC: 0.814, recall: 0.634). Although the prescribing data for dose-related collection are highly imbalanced, various techniques such as the following have allowed us to build high-performance prediction models: data preprocessing by SMOTE, stratified cross-validation, and BRF classifier corresponding to imbalanced data. ML is useful in complicated dose audits such as oral prednisolone.
Supplementary information: The online version contains supplementary material available at 10.1007/s41666-023-00128-3.
期刊介绍:
Journal of Healthcare Informatics Research serves as a publication venue for the innovative technical contributions highlighting analytics, systems, and human factors research in healthcare informatics.Journal of Healthcare Informatics Research is concerned with the application of computer science principles, information science principles, information technology, and communication technology to address problems in healthcare, and everyday wellness. Journal of Healthcare Informatics Research highlights the most cutting-edge technical contributions in computing-oriented healthcare informatics. The journal covers three major tracks: (1) analytics—focuses on data analytics, knowledge discovery, predictive modeling; (2) systems—focuses on building healthcare informatics systems (e.g., architecture, framework, design, engineering, and application); (3) human factors—focuses on understanding users or context, interface design, health behavior, and user studies of healthcare informatics applications. Topics include but are not limited to: · healthcare software architecture, framework, design, and engineering;· electronic health records· medical data mining· predictive modeling· medical information retrieval· medical natural language processing· healthcare information systems· smart health and connected health· social media analytics· mobile healthcare· medical signal processing· human factors in healthcare· usability studies in healthcare· user-interface design for medical devices and healthcare software· health service delivery· health games· security and privacy in healthcare· medical recommender system· healthcare workflow management· disease profiling and personalized treatment· visualization of medical data· intelligent medical devices and sensors· RFID solutions for healthcare· healthcare decision analytics and support systems· epidemiological surveillance systems and intervention modeling· consumer and clinician health information needs, seeking, sharing, and use· semantic Web, linked data, and ontology· collaboration technologies for healthcare· assistive and adaptive ubiquitous computing technologies· statistics and quality of medical data· healthcare delivery in developing countries· health systems modeling and simulation· computer-aided diagnosis

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


