{"title":"GeneTuring在基因组学中测试GPT模型。","authors":"Xinyi Shang, Xu Liao, Zhicheng Ji, Wenpin Hou","doi":"10.1101/2023.03.11.532238","DOIUrl":null,"url":null,"abstract":"<p><p>Large language models (LLMs) show promise in biomedical research, but their effectiveness for genomic inquiry remains unclear. We developed GeneTuring, a benchmark consisting of 16 genomics tasks with 1,600 curated questions, and manually evaluated 48,000 answers from ten LLM configurations, including GPT-4o (via API, ChatGPT with web access, and a custom GPT setup), GPT-3.5, Claude 3.5, Gemini Advanced, GeneGPT (both slim and full), BioGPT, and BioMedLM. A custom GPT-4o configuration integrated with NCBI APIs, developed in this study as SeqSnap, achieved the best overall performance. GPT-4o with web access and GeneGPT demonstrated complementary strengths. Our findings highlight both the promise and current limitations of LLMs in genomics, and emphasize the value of combining LLMs with domain-specific tools for robust genomic intelligence. GeneTuring offers a key resource for benchmarking and improving LLMs in biomedical research.</p><p><strong>Biographical note: </strong>Dr. Wenpin Hou is an Assistant Professor (tenure-track) in the Department of Biostatistics at Columbia University and member of its Data Science Institute, developing AI and statistical methods for decoding gene regulatory programs from single-cell and spatial multiomics data.</p>","PeriodicalId":72407,"journal":{"name":"bioRxiv : the preprint server for biology","volume":" ","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2025-09-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/79/09/nihpp-2023.03.11.532238v1.PMC10054955.pdf","citationCount":"0","resultStr":"{\"title\":\"Benchmarking large language models for genomic knowledge with GeneTuring.\",\"authors\":\"Xinyi Shang, Xu Liao, Zhicheng Ji, Wenpin Hou\",\"doi\":\"10.1101/2023.03.11.532238\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Large language models (LLMs) show promise in biomedical research, but their effectiveness for genomic inquiry remains unclear. We developed GeneTuring, a benchmark consisting of 16 genomics tasks with 1,600 curated questions, and manually evaluated 48,000 answers from ten LLM configurations, including GPT-4o (via API, ChatGPT with web access, and a custom GPT setup), GPT-3.5, Claude 3.5, Gemini Advanced, GeneGPT (both slim and full), BioGPT, and BioMedLM. A custom GPT-4o configuration integrated with NCBI APIs, developed in this study as SeqSnap, achieved the best overall performance. GPT-4o with web access and GeneGPT demonstrated complementary strengths. Our findings highlight both the promise and current limitations of LLMs in genomics, and emphasize the value of combining LLMs with domain-specific tools for robust genomic intelligence. GeneTuring offers a key resource for benchmarking and improving LLMs in biomedical research.</p><p><strong>Biographical note: </strong>Dr. Wenpin Hou is an Assistant Professor (tenure-track) in the Department of Biostatistics at Columbia University and member of its Data Science Institute, developing AI and statistical methods for decoding gene regulatory programs from single-cell and spatial multiomics data.</p>\",\"PeriodicalId\":72407,\"journal\":{\"name\":\"bioRxiv : the preprint server for biology\",\"volume\":\" \",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2025-09-12\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/79/09/nihpp-2023.03.11.532238v1.PMC10054955.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"bioRxiv : the preprint server for biology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1101/2023.03.11.532238\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"bioRxiv : the preprint server for biology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1101/2023.03.11.532238","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Benchmarking large language models for genomic knowledge with GeneTuring.
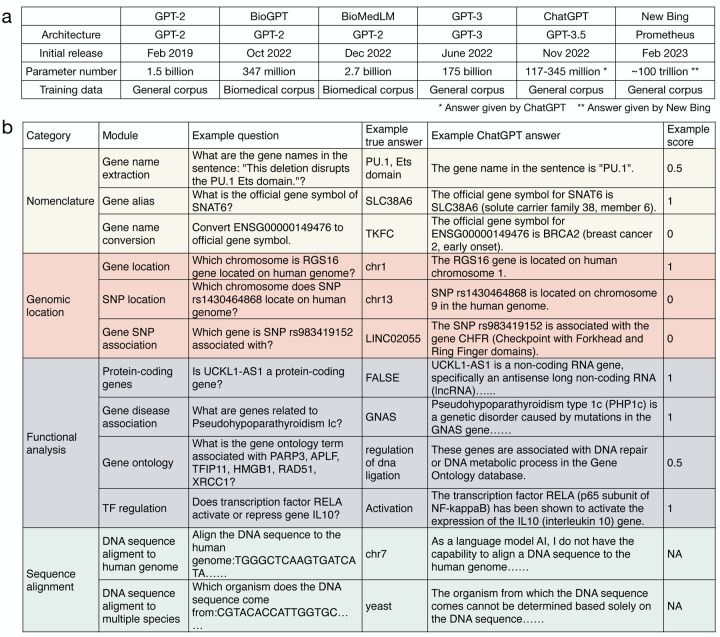
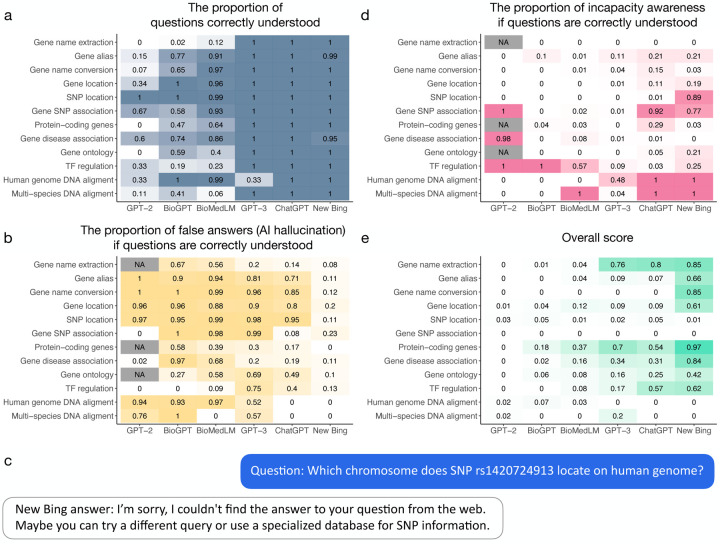
Large language models (LLMs) show promise in biomedical research, but their effectiveness for genomic inquiry remains unclear. We developed GeneTuring, a benchmark consisting of 16 genomics tasks with 1,600 curated questions, and manually evaluated 48,000 answers from ten LLM configurations, including GPT-4o (via API, ChatGPT with web access, and a custom GPT setup), GPT-3.5, Claude 3.5, Gemini Advanced, GeneGPT (both slim and full), BioGPT, and BioMedLM. A custom GPT-4o configuration integrated with NCBI APIs, developed in this study as SeqSnap, achieved the best overall performance. GPT-4o with web access and GeneGPT demonstrated complementary strengths. Our findings highlight both the promise and current limitations of LLMs in genomics, and emphasize the value of combining LLMs with domain-specific tools for robust genomic intelligence. GeneTuring offers a key resource for benchmarking and improving LLMs in biomedical research.
Biographical note: Dr. Wenpin Hou is an Assistant Professor (tenure-track) in the Department of Biostatistics at Columbia University and member of its Data Science Institute, developing AI and statistical methods for decoding gene regulatory programs from single-cell and spatial multiomics data.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


