{"title":"马修斯相关系数(MCC)应取代 ROC AUC,成为评估二元分类的标准指标。","authors":"Davide Chicco, Giuseppe Jurman","doi":"10.1186/s13040-023-00322-4","DOIUrl":null,"url":null,"abstract":"<p><p>Binary classification is a common task for which machine learning and computational statistics are used, and the area under the receiver operating characteristic curve (ROC AUC) has become the common standard metric to evaluate binary classifications in most scientific fields. The ROC curve has true positive rate (also called sensitivity or recall) on the y axis and false positive rate on the x axis, and the ROC AUC can range from 0 (worst result) to 1 (perfect result). The ROC AUC, however, has several flaws and drawbacks. This score is generated including predictions that obtained insufficient sensitivity and specificity, and moreover it does not say anything about positive predictive value (also known as precision) nor negative predictive value (NPV) obtained by the classifier, therefore potentially generating inflated overoptimistic results. Since it is common to include ROC AUC alone without precision and negative predictive value, a researcher might erroneously conclude that their classification was successful. Furthermore, a given point in the ROC space does not identify a single confusion matrix nor a group of matrices sharing the same MCC value. Indeed, a given (sensitivity, specificity) pair can cover a broad MCC range, which casts doubts on the reliability of ROC AUC as a performance measure. In contrast, the Matthews correlation coefficient (MCC) generates a high score in its [Formula: see text] interval only if the classifier scored a high value for all the four basic rates of the confusion matrix: sensitivity, specificity, precision, and negative predictive value. A high MCC (for example, MCC [Formula: see text] 0.9), moreover, always corresponds to a high ROC AUC, and not vice versa. In this short study, we explain why the Matthews correlation coefficient should replace the ROC AUC as standard statistic in all the scientific studies involving a binary classification, in all scientific fields.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"16 1","pages":"4"},"PeriodicalIF":4.0000,"publicationDate":"2023-02-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9938573/pdf/","citationCount":"0","resultStr":"{\"title\":\"The Matthews correlation coefficient (MCC) should replace the ROC AUC as the standard metric for assessing binary classification.\",\"authors\":\"Davide Chicco, Giuseppe Jurman\",\"doi\":\"10.1186/s13040-023-00322-4\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Binary classification is a common task for which machine learning and computational statistics are used, and the area under the receiver operating characteristic curve (ROC AUC) has become the common standard metric to evaluate binary classifications in most scientific fields. The ROC curve has true positive rate (also called sensitivity or recall) on the y axis and false positive rate on the x axis, and the ROC AUC can range from 0 (worst result) to 1 (perfect result). The ROC AUC, however, has several flaws and drawbacks. This score is generated including predictions that obtained insufficient sensitivity and specificity, and moreover it does not say anything about positive predictive value (also known as precision) nor negative predictive value (NPV) obtained by the classifier, therefore potentially generating inflated overoptimistic results. Since it is common to include ROC AUC alone without precision and negative predictive value, a researcher might erroneously conclude that their classification was successful. Furthermore, a given point in the ROC space does not identify a single confusion matrix nor a group of matrices sharing the same MCC value. Indeed, a given (sensitivity, specificity) pair can cover a broad MCC range, which casts doubts on the reliability of ROC AUC as a performance measure. In contrast, the Matthews correlation coefficient (MCC) generates a high score in its [Formula: see text] interval only if the classifier scored a high value for all the four basic rates of the confusion matrix: sensitivity, specificity, precision, and negative predictive value. A high MCC (for example, MCC [Formula: see text] 0.9), moreover, always corresponds to a high ROC AUC, and not vice versa. In this short study, we explain why the Matthews correlation coefficient should replace the ROC AUC as standard statistic in all the scientific studies involving a binary classification, in all scientific fields.</p>\",\"PeriodicalId\":48947,\"journal\":{\"name\":\"Biodata Mining\",\"volume\":\"16 1\",\"pages\":\"4\"},\"PeriodicalIF\":4.0000,\"publicationDate\":\"2023-02-17\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9938573/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biodata Mining\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s13040-023-00322-4\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-023-00322-4","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
The Matthews correlation coefficient (MCC) should replace the ROC AUC as the standard metric for assessing binary classification.
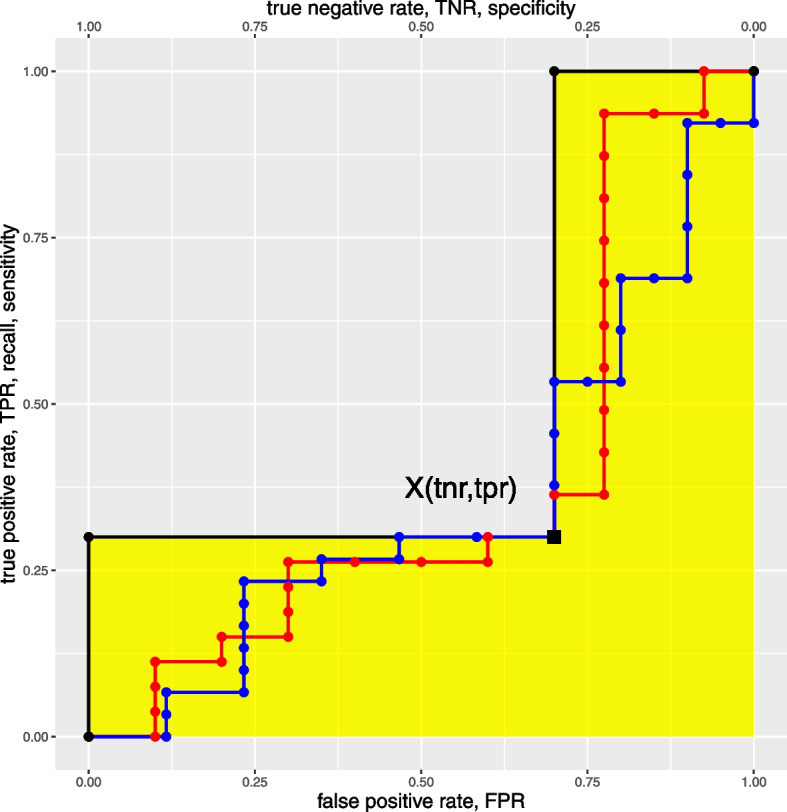
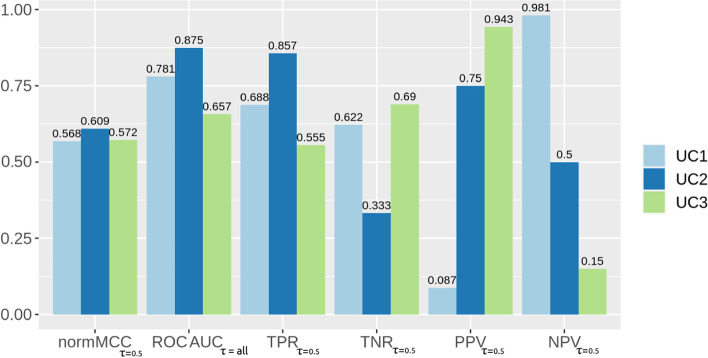
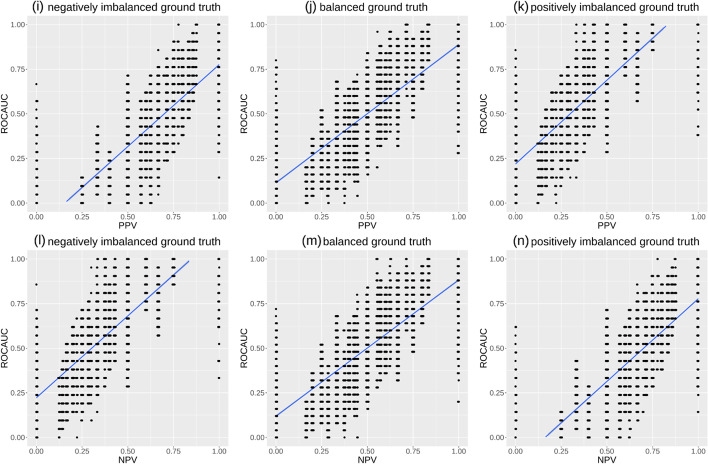
Binary classification is a common task for which machine learning and computational statistics are used, and the area under the receiver operating characteristic curve (ROC AUC) has become the common standard metric to evaluate binary classifications in most scientific fields. The ROC curve has true positive rate (also called sensitivity or recall) on the y axis and false positive rate on the x axis, and the ROC AUC can range from 0 (worst result) to 1 (perfect result). The ROC AUC, however, has several flaws and drawbacks. This score is generated including predictions that obtained insufficient sensitivity and specificity, and moreover it does not say anything about positive predictive value (also known as precision) nor negative predictive value (NPV) obtained by the classifier, therefore potentially generating inflated overoptimistic results. Since it is common to include ROC AUC alone without precision and negative predictive value, a researcher might erroneously conclude that their classification was successful. Furthermore, a given point in the ROC space does not identify a single confusion matrix nor a group of matrices sharing the same MCC value. Indeed, a given (sensitivity, specificity) pair can cover a broad MCC range, which casts doubts on the reliability of ROC AUC as a performance measure. In contrast, the Matthews correlation coefficient (MCC) generates a high score in its [Formula: see text] interval only if the classifier scored a high value for all the four basic rates of the confusion matrix: sensitivity, specificity, precision, and negative predictive value. A high MCC (for example, MCC [Formula: see text] 0.9), moreover, always corresponds to a high ROC AUC, and not vice versa. In this short study, we explain why the Matthews correlation coefficient should replace the ROC AUC as standard statistic in all the scientific studies involving a binary classification, in all scientific fields.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


