{"title":"一种保护隐私的医疗数据分布式分析平台。","authors":"Sascha Welten, Yongli Mou, Laurenz Neumann, Mehrshad Jaberansary, Yeliz Yediel Ucer, Toralf Kirsten, Stefan Decker, Oya Beyan","doi":"10.1055/s-0041-1740564","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>In recent years, data-driven medicine has gained increasing importance in terms of diagnosis, treatment, and research due to the exponential growth of health care data. However, data protection regulations prohibit data centralisation for analysis purposes because of potential privacy risks like the accidental disclosure of data to third parties. Therefore, alternative data usage policies, which comply with present privacy guidelines, are of particular interest.</p><p><strong>Objective: </strong>We aim to enable analyses on sensitive patient data by simultaneously complying with local data protection regulations using an approach called the Personal Health Train (PHT), which is a paradigm that utilises distributed analytics (DA) methods. The main principle of the PHT is that the analytical task is brought to the data provider and the data instances remain in their original location.</p><p><strong>Methods: </strong>In this work, we present our implementation of the PHT paradigm, which preserves the sovereignty and autonomy of the data providers and operates with a limited number of communication channels. We further conduct a DA use case on data stored in three different and distributed data providers.</p><p><strong>Results: </strong>We show that our infrastructure enables the training of data models based on distributed data sources.</p><p><strong>Conclusion: </strong>Our work presents the capabilities of DA infrastructures in the health care sector, which lower the regulatory obstacles of sharing patient data. We further demonstrate its ability to fuel medical science by making distributed data sets available for scientists or health care practitioners.</p>","PeriodicalId":49822,"journal":{"name":"Methods of Information in Medicine","volume":"61 S 01","pages":"e1-e11"},"PeriodicalIF":1.8000,"publicationDate":"2022-06-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/66/85/10-1055-s-0041-1740564.PMC9246511.pdf","citationCount":"16","resultStr":"{\"title\":\"A Privacy-Preserving Distributed Analytics Platform for Health Care Data.\",\"authors\":\"Sascha Welten, Yongli Mou, Laurenz Neumann, Mehrshad Jaberansary, Yeliz Yediel Ucer, Toralf Kirsten, Stefan Decker, Oya Beyan\",\"doi\":\"10.1055/s-0041-1740564\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>In recent years, data-driven medicine has gained increasing importance in terms of diagnosis, treatment, and research due to the exponential growth of health care data. However, data protection regulations prohibit data centralisation for analysis purposes because of potential privacy risks like the accidental disclosure of data to third parties. Therefore, alternative data usage policies, which comply with present privacy guidelines, are of particular interest.</p><p><strong>Objective: </strong>We aim to enable analyses on sensitive patient data by simultaneously complying with local data protection regulations using an approach called the Personal Health Train (PHT), which is a paradigm that utilises distributed analytics (DA) methods. The main principle of the PHT is that the analytical task is brought to the data provider and the data instances remain in their original location.</p><p><strong>Methods: </strong>In this work, we present our implementation of the PHT paradigm, which preserves the sovereignty and autonomy of the data providers and operates with a limited number of communication channels. We further conduct a DA use case on data stored in three different and distributed data providers.</p><p><strong>Results: </strong>We show that our infrastructure enables the training of data models based on distributed data sources.</p><p><strong>Conclusion: </strong>Our work presents the capabilities of DA infrastructures in the health care sector, which lower the regulatory obstacles of sharing patient data. We further demonstrate its ability to fuel medical science by making distributed data sets available for scientists or health care practitioners.</p>\",\"PeriodicalId\":49822,\"journal\":{\"name\":\"Methods of Information in Medicine\",\"volume\":\"61 S 01\",\"pages\":\"e1-e11\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2022-06-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/66/85/10-1055-s-0041-1740564.PMC9246511.pdf\",\"citationCount\":\"16\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Methods of Information in Medicine\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1055/s-0041-1740564\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, INFORMATION SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Methods of Information in Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1055/s-0041-1740564","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
A Privacy-Preserving Distributed Analytics Platform for Health Care Data.
Background: In recent years, data-driven medicine has gained increasing importance in terms of diagnosis, treatment, and research due to the exponential growth of health care data. However, data protection regulations prohibit data centralisation for analysis purposes because of potential privacy risks like the accidental disclosure of data to third parties. Therefore, alternative data usage policies, which comply with present privacy guidelines, are of particular interest.
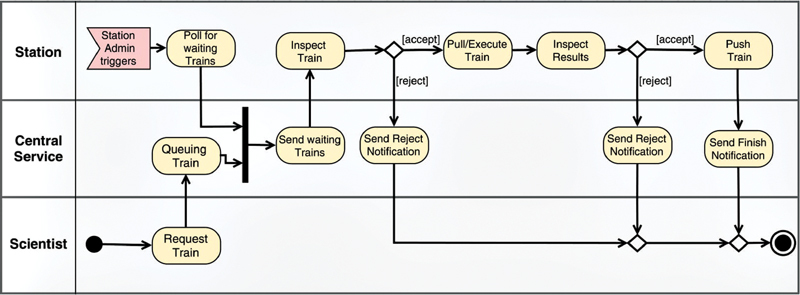
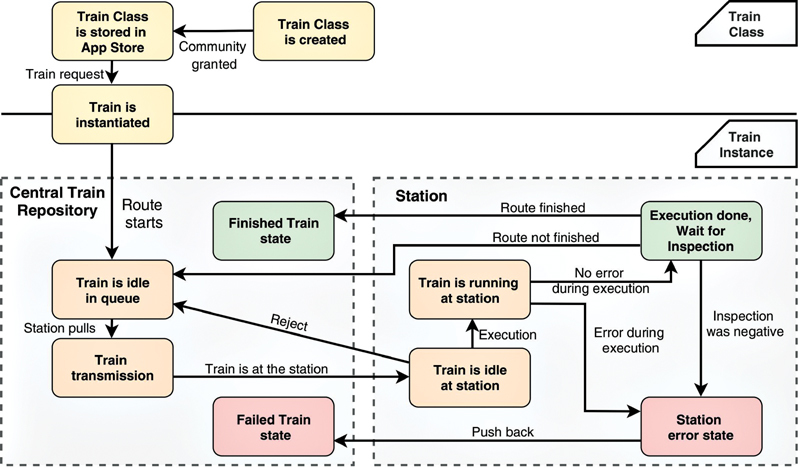
Objective: We aim to enable analyses on sensitive patient data by simultaneously complying with local data protection regulations using an approach called the Personal Health Train (PHT), which is a paradigm that utilises distributed analytics (DA) methods. The main principle of the PHT is that the analytical task is brought to the data provider and the data instances remain in their original location.
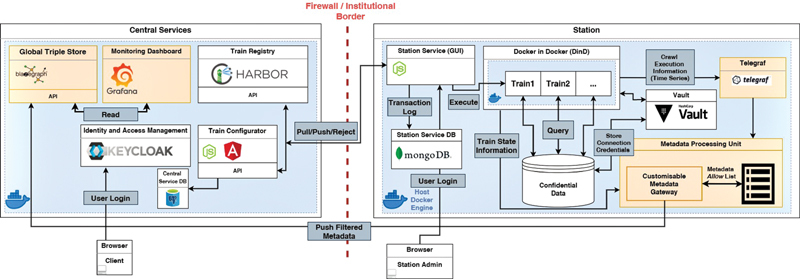
Methods: In this work, we present our implementation of the PHT paradigm, which preserves the sovereignty and autonomy of the data providers and operates with a limited number of communication channels. We further conduct a DA use case on data stored in three different and distributed data providers.
Results: We show that our infrastructure enables the training of data models based on distributed data sources.
Conclusion: Our work presents the capabilities of DA infrastructures in the health care sector, which lower the regulatory obstacles of sharing patient data. We further demonstrate its ability to fuel medical science by making distributed data sets available for scientists or health care practitioners.
期刊介绍:
Good medicine and good healthcare demand good information. Since the journal''s founding in 1962, Methods of Information in Medicine has stressed the methodology and scientific fundamentals of organizing, representing and analyzing data, information and knowledge in biomedicine and health care. Covering publications in the fields of biomedical and health informatics, medical biometry, and epidemiology, the journal publishes original papers, reviews, reports, opinion papers, editorials, and letters to the editor. From time to time, the journal publishes articles on particular focus themes as part of a journal''s issue.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


