Matthew R P Parker, Laura L E Cowen, Jiguo Cao, Lloyd T Elliott
{"title":"复制计数和批量标记隐藏人口模型的计算效率和精度。","authors":"Matthew R P Parker, Laura L E Cowen, Jiguo Cao, Lloyd T Elliott","doi":"10.1007/s13253-022-00509-y","DOIUrl":null,"url":null,"abstract":"<p><p>We address two computational issues common to open-population <i>N</i>-mixture models, hidden integer-valued autoregressive models, and some hidden Markov models. The first issue is computation time, which can be dramatically improved through the use of a fast Fourier transform. The second issue is tractability of the model likelihood function for large numbers of hidden states, which can be solved by improving numerical stability of calculations. As an illustrative example, we detail the application of these methods to the open-population <i>N</i>-mixture models. We compare computational efficiency and precision between these methods and standard methods employed by state-of-the-art ecological software. We show faster computing times (a <math><mrow><mo>∼</mo> <mn>6</mn></mrow> </math> to <math><mrow><mo>∼</mo> <mn>30</mn></mrow> </math> times speed improvement for population size upper bounds of 500 and 1000, respectively) over state-of-the-art ecological software for <i>N</i>-mixture models. We also apply our methods to compute the size of a large elk population using an <i>N</i>-mixture model and show that while our methods converge, previous software cannot produce estimates due to numerical issues. These solutions can be applied to many ecological models to improve precision when logs of sums exist in the likelihood function and to improve computational efficiency when convolutions are present in the likelihood function. Supplementary materials accompanying this paper appear online. Supplementary materials for this article are available at 10.1007/s13253-022-00509-y.</p>","PeriodicalId":56336,"journal":{"name":"Journal of Agricultural Biological and Environmental Statistics","volume":"28 1","pages":"43-58"},"PeriodicalIF":1.1000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9434542/pdf/","citationCount":"0","resultStr":"{\"title\":\"Computational Efficiency and Precision for Replicated-Count and Batch-Marked Hidden Population Models.\",\"authors\":\"Matthew R P Parker, Laura L E Cowen, Jiguo Cao, Lloyd T Elliott\",\"doi\":\"10.1007/s13253-022-00509-y\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>We address two computational issues common to open-population <i>N</i>-mixture models, hidden integer-valued autoregressive models, and some hidden Markov models. The first issue is computation time, which can be dramatically improved through the use of a fast Fourier transform. The second issue is tractability of the model likelihood function for large numbers of hidden states, which can be solved by improving numerical stability of calculations. As an illustrative example, we detail the application of these methods to the open-population <i>N</i>-mixture models. We compare computational efficiency and precision between these methods and standard methods employed by state-of-the-art ecological software. We show faster computing times (a <math><mrow><mo>∼</mo> <mn>6</mn></mrow> </math> to <math><mrow><mo>∼</mo> <mn>30</mn></mrow> </math> times speed improvement for population size upper bounds of 500 and 1000, respectively) over state-of-the-art ecological software for <i>N</i>-mixture models. We also apply our methods to compute the size of a large elk population using an <i>N</i>-mixture model and show that while our methods converge, previous software cannot produce estimates due to numerical issues. These solutions can be applied to many ecological models to improve precision when logs of sums exist in the likelihood function and to improve computational efficiency when convolutions are present in the likelihood function. Supplementary materials accompanying this paper appear online. Supplementary materials for this article are available at 10.1007/s13253-022-00509-y.</p>\",\"PeriodicalId\":56336,\"journal\":{\"name\":\"Journal of Agricultural Biological and Environmental Statistics\",\"volume\":\"28 1\",\"pages\":\"43-58\"},\"PeriodicalIF\":1.1000,\"publicationDate\":\"2023-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9434542/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Agricultural Biological and Environmental Statistics\",\"FirstCategoryId\":\"100\",\"ListUrlMain\":\"https://doi.org/10.1007/s13253-022-00509-y\",\"RegionNum\":4,\"RegionCategory\":\"数学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Agricultural Biological and Environmental Statistics","FirstCategoryId":"100","ListUrlMain":"https://doi.org/10.1007/s13253-022-00509-y","RegionNum":4,"RegionCategory":"数学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"BIOLOGY","Score":null,"Total":0}
Computational Efficiency and Precision for Replicated-Count and Batch-Marked Hidden Population Models.
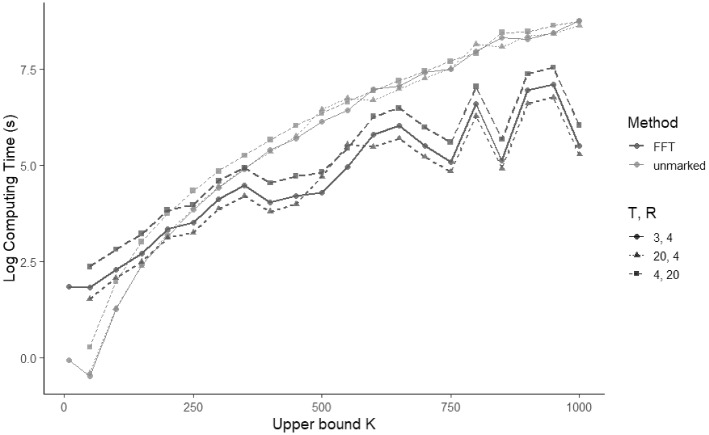
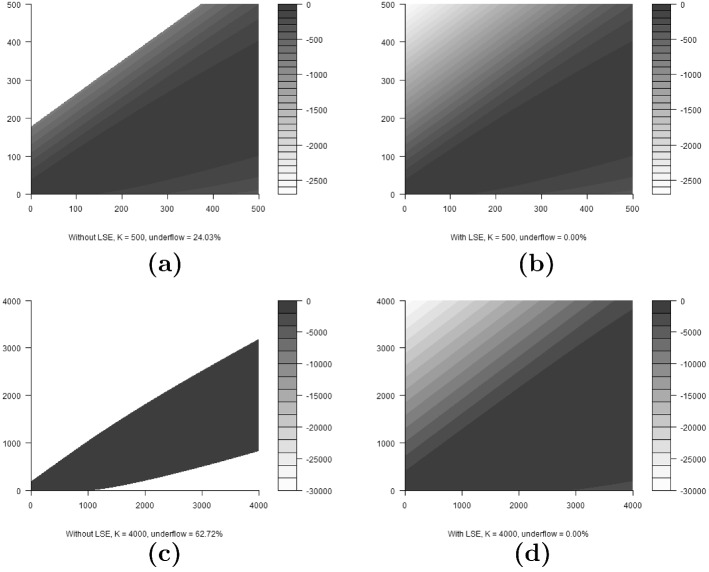
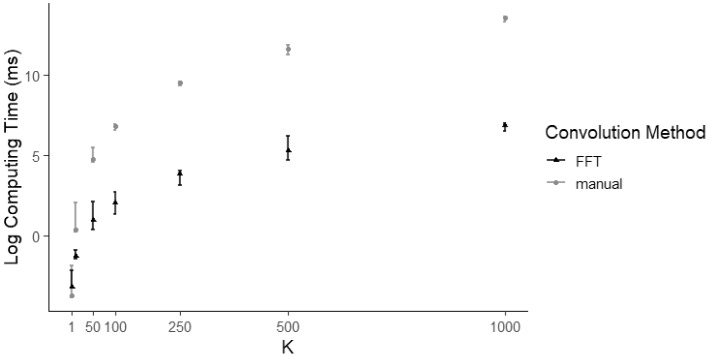
We address two computational issues common to open-population N-mixture models, hidden integer-valued autoregressive models, and some hidden Markov models. The first issue is computation time, which can be dramatically improved through the use of a fast Fourier transform. The second issue is tractability of the model likelihood function for large numbers of hidden states, which can be solved by improving numerical stability of calculations. As an illustrative example, we detail the application of these methods to the open-population N-mixture models. We compare computational efficiency and precision between these methods and standard methods employed by state-of-the-art ecological software. We show faster computing times (a to times speed improvement for population size upper bounds of 500 and 1000, respectively) over state-of-the-art ecological software for N-mixture models. We also apply our methods to compute the size of a large elk population using an N-mixture model and show that while our methods converge, previous software cannot produce estimates due to numerical issues. These solutions can be applied to many ecological models to improve precision when logs of sums exist in the likelihood function and to improve computational efficiency when convolutions are present in the likelihood function. Supplementary materials accompanying this paper appear online. Supplementary materials for this article are available at 10.1007/s13253-022-00509-y.
期刊介绍:
The Journal of Agricultural, Biological and Environmental Statistics (JABES) publishes papers that introduce new statistical methods to solve practical problems in the agricultural sciences, the biological sciences (including biotechnology), and the environmental sciences (including those dealing with natural resources). Papers that apply existing methods in a novel context are also encouraged. Interdisciplinary papers and papers that illustrate the application of new and important statistical methods using real data are strongly encouraged. The journal does not normally publish papers that have a primary focus on human genetics, human health, or medical statistics.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


